
基于YOLOv5的无人机/遥感场景旋转目标检测的优化心得详解
共 7774字,需浏览 16分钟
·
2022-05-19 12:25
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
以下文章来源于:略略略@知乎
作者:略略略
编辑:极市平台
原文链接:https://zhuanlan.zhihu.com/p/358441134
本文仅用于学术分享,如有侵权,请联系后台作删文处理

前言:
现成的YOLOv5代码真的很香,不管口碑怎么样,我用着反正是挺爽的,毕竟一个开源项目学术价值和工程应用价值只要占其一就值得称赞,而且v5确实在项目上手这一块非常友好,建议大家自己上手体会一下。
本文默认读者对YOLOv5的原理和代码结构已经有了基础了解,如果从未接触过,可以参考这篇文章:
深度眸:进击的后浪yolov5深度可视化解析:https://zhuanlan.zhihu.com/p/183838757
目标检测方法所采取的边框标注方式要按照被检测物体本身的形状特征进行改变。原始YOLOv5项目的应用场景为自然场景下的目标,目标检测边框为水平矩形框(Horizontal Bounding Box,HBB),毕竟我们的视角就是水平视角。
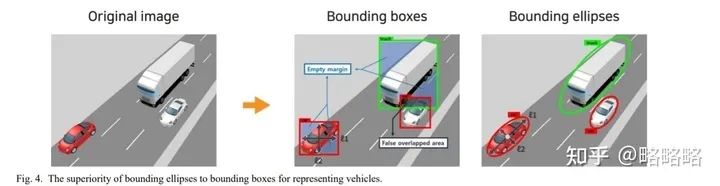
而当视角发生改变时,物体呈现在二维图像中的形状特征就会发生改变,为了更好的匹配图像特征,人们想出了多种边框的标记方法,比如交通监控(鸟瞰)视角下的物体可以采取椭圆边框进行标注:
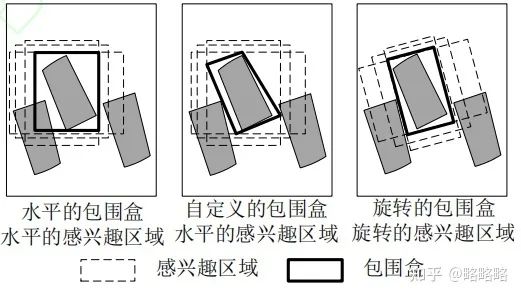
视角继续上升来到无人机/卫星的高度,俯视视角下的物体形状特征继续发生改变,此时边框标记方式就有了更多的选择:
至于你问选择适当的边框标注方式有什么作用,我个人的理解有以下两点:
标注方式越精准,提供给网络训练时的冗余信息就越少;先验越充分,网络的可学习方案就越少,有利于约束网络的训练方向和减少网络的收敛时间; 当目标物体过于紧密时,精准的标注方式可以避免被NMS”错杀“已经检出的目标。

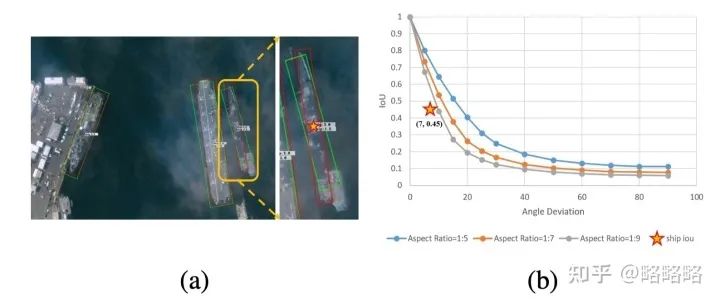
以本图为例,精准的标注方式可以确保紧密的物体之间的IOU为0;如果标注方式改为水平目标边框检测效果将惨不忍睹。
那么纯俯视角度(无人机/遥感视角)下的物体有哪些常见的标注方式呢?可以参考下面这篇文章,且yangxue作者提出的Circular Smooth Label也是YOLOv5改建的关键之处:
上面那篇文章的主要思想就是缓解旋转目标标注方式在网络训练时产生的边界问题, 这种边界问题其实可以一句话概括:由于学习的目标参数具有周期性,在周期变化的边界处会导致损失值突增,因此增大网络的学习难度。 这句话可以参考下图进行理解:
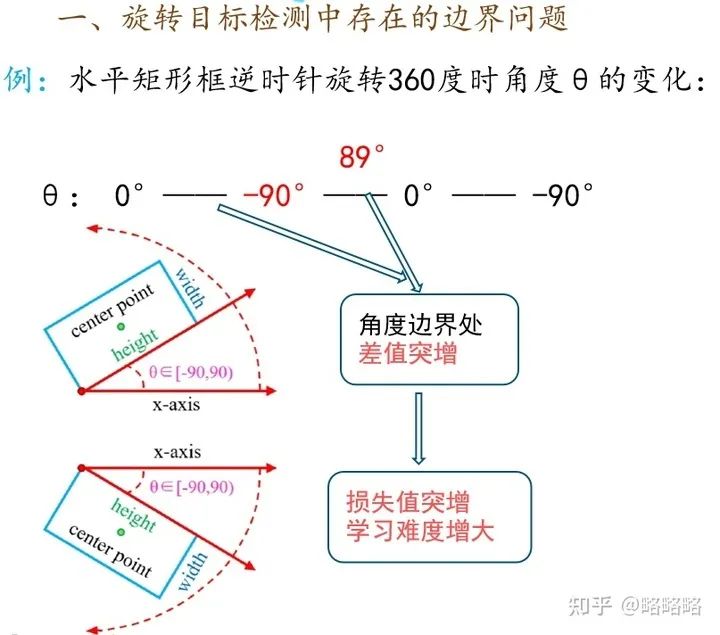
以180度回归的长边定义法中的θ为例,θ ∈[-90,90);正常训练情况下,网络预测的θ值为88,目标真实θ值为89,网络学习到的角度距离为1,真实情况下的两者差值为1;边界情况下,网络预测的θ值为89,目标真实θ值为-90,网络学习到的角度距离为179,真实情况下的两者差值为1.
那么如何处理边界问题呢:(以θ的边界问题为例)
寻找一种新的旋转目标定义方式,定义方式中不含具有周期变化性的参数,却又能表示周期旋转的目标物体,根本上杜绝边界问题的产生;(Anchor free/mask的思路,PolarDet、P-RSDet基于极坐标系表示一个任意四边形物体,BBA-Vectors、O^2-DNet基于向量来表示一个有向矩形,ROPDet、Beyond Bounding Box、Oriented Reppoints基于点集来表示一个任意形状的物体,) 从损失函数上入手,使用Smooth L1单独考虑每个参数时,赋予损失函数和角度同样的周期性,使得边界处θ之间差值可以很大,但loss变化实际很小;或者综合考虑所有回归参数的影响,使用旋转IoU损失函数也可以规避边界问题,不过RIoU不可导,近似可导的相关工作可以参考KLD、GWD,工程上实现RIoU可导的工作可以参考:https://github.com/csuhan/s2anet/blob/master/configs/rotated_iou/README.md θ由回归问题转为分类问题。(把连续问题直接离散化,避开边界情况)
其中2,3yangxue大佬都有过相应的解决方案,大家可以去他的主页参考。CSL就是3的思想体现,只不过CSL考虑的更多,因为当θ变为分类问题后,网络就无法学习到角度距离信息了,比如真实角度为-90,网络预测成89和-89产生的损失值我们期望是一样的,因为角度距离实际上都是1。
所以CSL实际上是一个用分类实现回归思想的解决方案, 具体细节大家移步去上面的文章。我们直接用成果,基于180度回归的长边定义法中的参数只有θ存在边界问题,而CSL刚好又能处理θ的边界问题,那么我们”暂且认为“CSL+长边定义法的组合是比较优的。之所以说是”暂且“是因为yangxue大佬又在最新的文章里面又提出了这种方式的缺点:

当时我的心情如下,那还是方法1的anchor free方案比较好,一劳永逸;

但是这篇文章有部分我还没有理解透彻,我们还是只用CSL+长边定义法就行了,后期的升级工作交给各位了。
标注方案确定之后,就可以开始一系列的改建工作了。
正文:
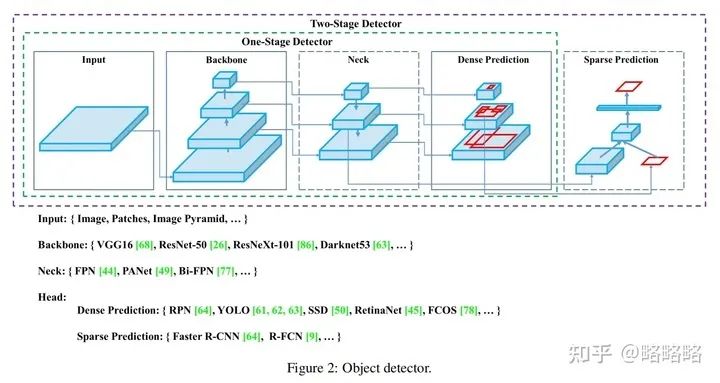
基本所有基于深度学习的目标检测器项目的结构都分为:
数据加载器(图像预处理)--> BackBone(提取目标特征) --> Neck(收集组合目标特征) --> Head(预测部分) --> 损失函数部分
一、数据加载部分
首先我们必须熟知自己的数据在进入网络之前的数据形式是什么样的,因为我们采用的是长边定义法,所以我们的注释文件格式为:
[ classid x_c y_c longside shortside Θ ] Θ∈[0, 180)
* longside: 旋转矩形框的最长边
* shortside: 与最长边对应的另一边
* Θ: x轴顺时针旋转遇到最长边所经过的角度
至于数据形式如何转换,利用好cv2.minAreaRect()函数+总结规律就可以,我的另一篇文章里讲的比较清楚,大家可以移步:
略略略:DOTA数据格式转YOLO数据格式工具(cv2.minAreaRect踩坑记录):https://zhuanlan.zhihu.com/p/356416158)
注意opencv4.1.2版本cv2.minAreaRect()函数生成的最小外接矩形框(x,y,w,h,θ)的几个大坑:
(1) 在绝大数情况下 Θ∈[-90, 0);
(2) 部分水平或垂直的目标边框,其θ值为0;
(3) width或height有时输出0, 与此同时Θ = 90;
(4) 输出的width或height有时会超过图片本身的宽高,即归一化时数据>1。
接下来图像数据与label数据进入到程序中,我们必须熟知在进入backbone之前,数据加载器流程中labels数据的维度变化。
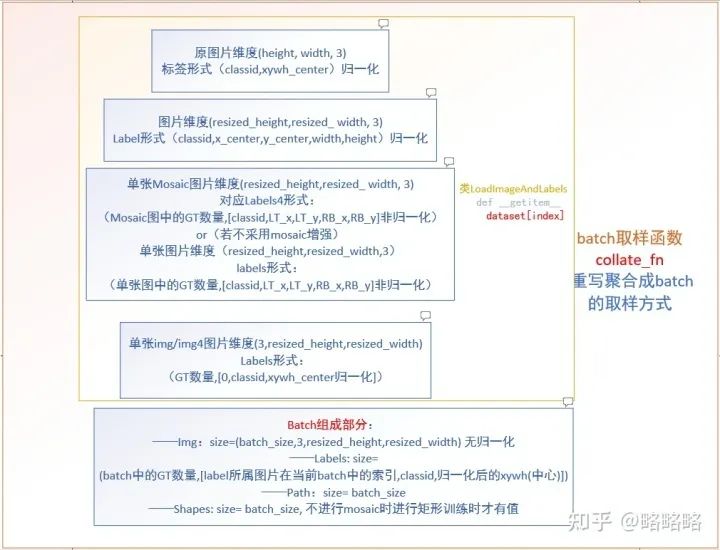
原始yolov5中,labels数据维度一直以(X_LT, Y_LT, X_RB, Y_RB)左上角右下角两点坐标表示水平矩形框的形式存在,并一直在做归一化和反归一化操作
由于我们采用的边框定义法是[x_c y_c longside shortside Θ],边框的角度信息只存在于θ中,我们完全可以将 [x_c y_c longside shortside] 视为水平目标边框,因此在数据加载部分我们只需要在labels原始数据的基础上添加一个θ维度,只要不是涉及到会引起labels角度变化的代码都不需要更改其处理逻辑。
注意: 数据加载器中存在大量的归一化和反归一化的操作,以及大量涉及到图像宽高度的数据变化,因此网络输入的图像size:HEIGHT 必须= WIDTH,因为长边定义法中的longside和shorside与图像的宽高没有严格的对应关系。
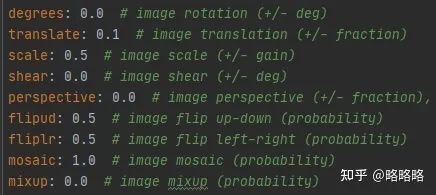
数据加载器中涉及三类数据增强方式:Mosaic,random_perspective(仿射矩阵增强),普通数据增强方式。
其中Mosaic,仿射矩阵增强都是针对(X_LT, Y_LT, X_RB, Y_RB)数据格式进行增强,修改时添加θ维度就可以,不过仿射矩阵增强函数内共有 Translation、Shear、Rotation、Scale、Perspective、Center 6种数据增强方式,其中旋转与形变仿射的变换会引起目标角度上的改变。
所以只要超参数中的 ['perspective']=0,['degrees']=0 ,这块函数代码就不需要修改逻辑部分,为了方便我们直接把涉及到角度的增强放在最后的普通数据增强方式中。
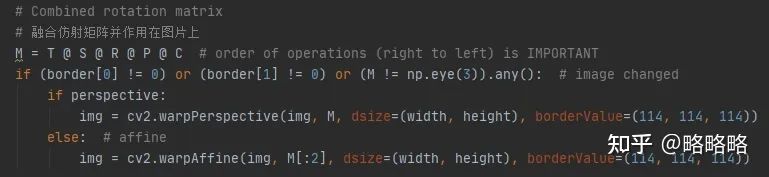
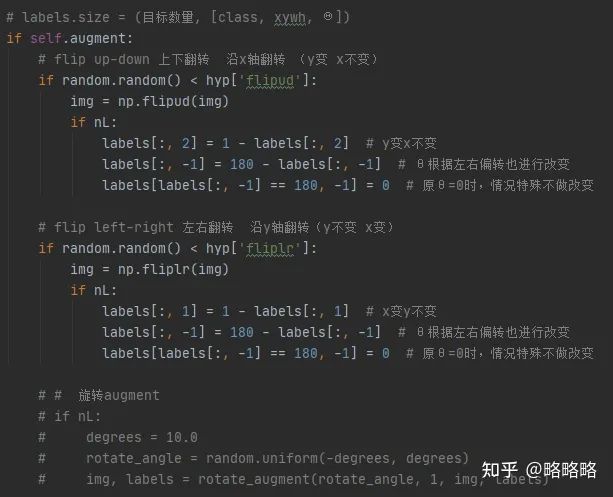
注意:Mosaic操作中会同时触发MixUp数据增强操作,但是在遥感/无人机应用场景中我个人认为并不适用,首先背景复杂就是该场景中的普遍难题,MixUp会融合两张图像,图像中的小目标会掺杂另一张图的背景信息(包含形似物或噪声),从而影响小目标的特征提取。(不过一切以实验结果为准)
二、Backbone部分、Neck部分
提取图像特征层的结构都不需要改动。
三、Head部分
head部分也就是yolo.py文件中的Detect类,由于我们将θ转为分类问题,因此每个anchor负责预测的参数数量为 (x_c y_c longside shortside score)+num_classes+angle_classes。修改Detect类的构造函数即可。
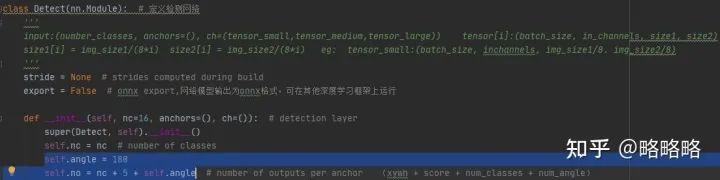
四、损失函数部分
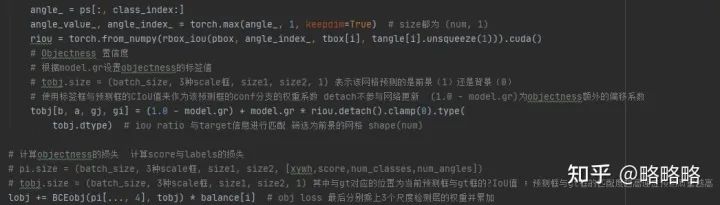
损失函数共有四个部分:置信度损失、class分类损失、θ角度分类损失、bbox边框回归损失。
(1)计算损失前的准备工作
损失的计算需要 targets 与 predicts,每个数据的维度都要有所对应,因此需要general.py文件中的build_targets函数生成目标真实GT的类别信息列表、边框参数信息列表、Anchor索引列表、Anchor尺寸信息列表、角度类别信息列表。
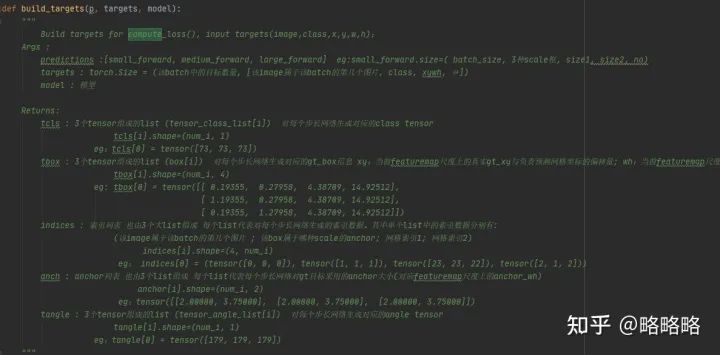
其中Anchor索引列表用于检索网络预测结果中对应的anchor,从而将其标记为正样本。yolov5为了保证正样本的数量,在正样本标记策略中采用了比较暴力的策略:原本yolov3仅仅采用当前GT中心所在的网格中的anchor进行正样本标记,而yolov5不仅采用当前网格中的anchor标记为正样本,同时还会标记相邻两个网格的anchor为正样本。
这种处理逻辑个人暂不评价好坏,但是yolov5源码在代码实现上显然考虑不够周全,目标中心所属网格如果刚好在图像的边界位置,yolov5的源码有时会输出超过featuremap尺寸的索引。这种bug表现在训练中就是某个时刻yolov5的训练就会中断:
Traceback (most recent call last):
File "train.py", line 457, in
train(hyp, opt, device, tb_writer)
File "train.py", line 270, in train
loss, loss_items = compute_loss(pred, targets.to(device), model) # loss scaled by batch_size
File "/mnt/G/1125/rotation-yolov5-master/utils/general.py", line 530, in compute_loss
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
RuntimeError: CUDA error: device-side assert triggered
上述报错显然是索引时超出数组取值范围的问题,解决方法也很简单,先查询是哪些参数超出了索引范围,当运行出错时,进入pdb调试,打印当前所有索引参数:
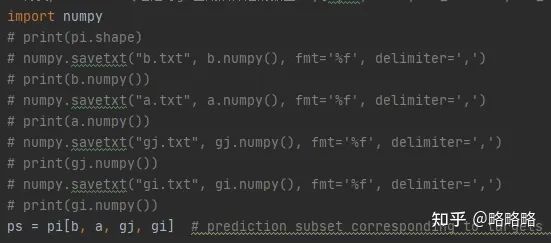
然后就发现网格索引gj,gi偶尔会超出当前featuremap的索引范围。(举例:featuremap大小为32×32,网格索引范围为0-31,但是build_targets函数偶尔会输出索引值32,此时出现bug,训练中断)
然而我当时在yolov5项目源码的Issues中却发现没人提交这种问题,原因也很简单,自然场景的下的目标很难标注在图片的边界位置,但是遥感/无人机图像显然相反,由于会经过裁剪,极其容易出现目标标注在边界位置的情况, 如下图所示:

这个BUG属于yolov5源码build_targets函数生成anchor索引时考虑不周全导致的,解决办法也很简单,在生成的索引处加上数值范围限制(坏处就是可能出现网格重复利用的情况,比较浪费):
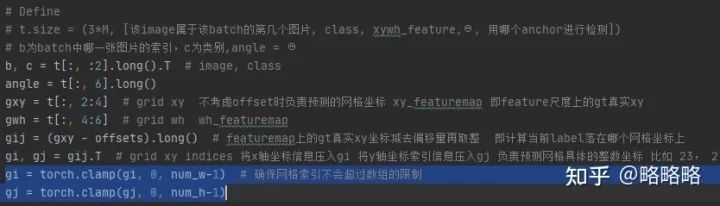
2021.04.25更新:
重复利用就重复利用呗(~破罐破摔!~),本来yolov5的跨网格正负样本标记方式就会产生同一个anchor与不同gt进行loss计算的问题,这个地方感觉还有很多地方可以优化,但就是想不明白这样子回归明明会产生二义性问题为什么效果还是很好?
之后的改建部分也比较机械,在compute_loss函数和build_targets函数中添加θ角度信息的处理即可,主要注意数据索引的代码块就可以,由于添加了‘θ’ 180个通道,所以函数中所有的索引部分都要更改。
补充:
今天(2021年3月21日) 我又去yolov5的issues上看了看,似乎20年11月份修复了这个问题。我这个是基于20年10月11日的代码改建的,要是晚下载几天就好了,兴许能避开这个坑。
又看了下新的yolov5源码,很多地方大换血...... 改建的速度还没人家更新的速度快。
(2)计算损失
class分类损失:
无需更改,注意数据索引部分即可。
θ角度分类损失:
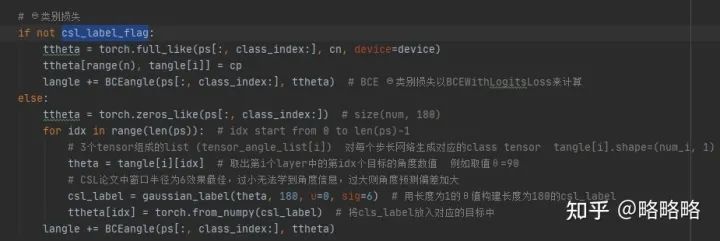
由于我们添加的θ是分类任务,照葫芦画瓢,添加分类损失就可以了,值得注意的是θ部分的损失我们有两种方案:
一种就是正常的分类损失,同类别损失一样:BCEWithLogitsLoss; 先将GT的θ label经CSL处理后,再计算类别损失:BCEWithLogitsLoss。
项目代码中同时实现了两种方案,由csl_label_flag进行控制,csl_label_flag为True则进行CSL处理,否则计算正常分类损失,方便大家查看CSL在自己数据集上的提升效果:
bbox边框回归损失:
yolov5源码中边框损失函数采用的是IOU/GIOU/CIOU/DIOU,适用于水平矩形边框之间计算IOU,原本是不适用于旋转框之间计算IOU的。由于框会旋转等原因,计算两个旋转框之间的IOU公式通常都不可导,如果θ为回归任务,势必要通过旋转IOU损失函数进行反向传播从而调整自身参数,大多数旋转检测器的处理办法都是将不可导的旋转IOU损失函数进行近似,使得网络可以正常进行训练。
不过因为我们将θ视为分类任务来处理,相当于将角度信息与边框参数信息解耦,所以旋转框的损失计算部分也分为角度损失和水平边框损失两个部分,因此源码部分可以不进行改动,边框回归损失部分依旧采用IOU/GIOU/CIOU/DIOU损失函数。
置信度损失:
这一部分我们需要考虑清楚,yolov5源码是将GT水平边框与预测水平边框的IOU/GIOU/CIOU/DIOU值作为该预测框的置信度分支的权重系数,由于改建的情况特殊(水平边框+角度),我们有两种选择:
置信度分支的权重系数依然选择水平边框的之间的IOU/GIOU/CIOU/DIOU; 置信度分支的权重系数为旋转框IOU。
方案1相当于完全解耦预测角度与预测置信度之间的关联,置信度只与边框参数有关联,但事实上角度的一点偏差对旋转框IOU的影响是很大的,这种做法可能会影响网络最后对目标的score预测,导致部分明明角度预测错误但是边框参数预测正确的冗余框有过大的score,从而NMS无法滤除,最终影响检测精度。
2021.04.22更新:
方案1速度比方案2训练快很多,gpu利用率也更稳定,而且预测出来的框的置信度相比来说会更高,就是可能错检的情况会多一点(θloss收敛正常,置信度loss收敛正常的话该情况会得到明显缓解)
方案2除了错检情况少一点以外,其余都是缺点,大家可以自行对比尝试。不过缺点后期可以通过cuda加速来改善,毕竟DOTA_devkit提供的C++库计算效率确实不高。再加上代码不是自己写的,想直接套用别的旋转IoU代码就只能用时间效率贼低的for循环来做。
方案2自然是为了避免上述情况的产生,此外也是对将角度解耦出去的一种”补偿“。(至于网络能否学到这一层补偿那就不得而知,毕竟conf分支的权重系数不会通过反向传播的方式进行更新——detach的参数不会参与网络训练)
不会计算旋转IOU也没关系,DOTA数据集的作者额外提供了一个DOTA_devkit工具,里面有现成的C++库,我们直接调用即可。
五、其他修改部分
数据加载器(图像预处理)--> BackBone(提取目标特征) --> Neck(收集组合目标特征) --> Head(预测部分) --> 损失函数部分
以上部分基本修改完毕,接下来就是可视化的部分,利用好Opencv的三个函数即可:
# rect = cv2.minAreaRect(poly) # 得到poly最小外接矩形的(中心(x,y), (宽,高), 旋转角度)
# box = np.float32(cv2.boxPoints(rect)) # 返回最小外接矩形rect的四个点的坐标
# cv2.drawContours(image=img, contours=[poly], contourIdx=-1, color=color, thickness=2*tl)
大家可以参考我上传的项目代码,里面基本每段代码都会有我的注解(主要是当时自己刚开始看yolov5源码,每句话都有注释)。


项目代码
本文仅做学术分享,如有侵权,请联系删文。