
【45期】盘点那些必问的数据结构算法题之基础排序
程序员的成长之路
共 942字,需浏览 2分钟
·
2020-09-24 15:52

阅读本文大概需要 6.5 分钟。
来自:juejin.im/post/5bacdd2b5188255c3f6be3c2
0 概述
本文代码:https://github.com/shishujuan/dsalg/tree/master/code/alg/sort
1 插入排序
/**
* 插入排序
*/
void insertSort(int a[], int n)
{
int i, j;
for (i = 1; i < n; i++) {
/*
* 循环不变式:a[0...i-1]有序。每次迭代开始前,a[0...i-1]有序,
* 循环结束后i=n,a[0...n-1]有序
* */
int key = a[i];
for (j = i; j > 0 && a[j-1] > key; j--) {
a[j] = a[j-1];
}
a[j] = key;
}
}
2 希尔排序
/**
* 希尔排序
*/
void shellSort(int a[], int n)
{
int gap;
for (gap = n/2; gap > 0; gap /= 2) {
int i;
for (i = gap; i < n; i++) {
int key = a[i], j;
for (j = i; j >= gap && key < a[j-gap]; j -= gap) {
a[j] = a[j-gap];
}
a[j] = key;
}
}
}
3 选择排序
/**
* 选择排序
*/
void selectSort(int a[], int n)
{
int i, j, min, tmp;
for (i = 0; i < n-1; i++) {
min = i;
for (j = i+1; j < n; j++) {
if (a[j] < a[min])
min = j;
}
if (min != i)
tmp = a[i], a[i] = a[min], a[min] = tmp; //交换a[i]和a[min]
}
}
初始时,i=0,a[0…-1] 为空,显然成立。
每次执行完成后,a[0…i] 包含 a 中最小的 i+1 个数,且有序。即第一次执行完成后,a[0…0] 包含 a 最小的 1 个数,且有序。
循环结束后,i=n-1,则 a[0…n-2]包含 a 最小的 n-1 个数,且已经有序。所以整个数组有序。
4 冒泡排序
/**
* 冒泡排序-经典版
*/
void bubbleSort(int a[], int n)
{
int i, j, tmp;
for (i = 0; i < n; i++) {
for (j = n-1; j >= i+1; j--) {
if (a[j] < a[j-1])
tmp = a[j], a[j] = a[j-1], a[j-1] = tmp;
}
}
}
/**
* 冒泡排序-优化版
*/
void betterBubbleSort(int a[], int n)
{
int tmp, i, j;
for (i = 0; i < n; i++) {
int sorted = 1;
for (j = n-1; j >= i+1; j--) {
if (a[j] < a[j-1]) {
tmp = a[j], a[j] = a[j-1], a[j-1] = tmp;
sorted = 0;
}
}
if (sorted)
return ;
}
}
5 计数排序

/**
* 计数排序
*/
void countingSort(int a[], int n)
{
int i, j;
int *b = (int *)malloc(sizeof(int) * n);
int k = maxOfIntArray(a, n); // 求数组最大元素
int *c = (int *)malloc(sizeof(int) * (k+1)); //辅助数组
for (i = 0; i <= k; i++)
c[i] = 0;
for (j = 0; j < n; j++)
c[a[j]] = c[a[j]] + 1; //c[i]包含等于i的元素个数
for (i = 1; i <= k; i++)
c[i] = c[i] + c[i-1]; //c[i]包含小于等于i的元素个数
for (j = n-1; j >= 0; j--) { // 赋值语句
b[c[a[j]]-1] = a[j]; //结果存在b[0...n-1]中
c[a[j]] = c[a[j]] - 1;
}
/*方便测试代码,这一步赋值不是必须的*/
for (i = 0; i < n; i++) {
a[i] = b[i];
}
free(b);
free(c);
}
6 归并排序
/*
* 归并排序-递归
* */
void mergeSort(int a[], int l, int u)
{
if (l < u) {
int m = l + (u-l)/2;
mergeSort(a, l, m);
mergeSort(a, m + 1, u);
merge(a, l, m, u);
}
}
/**
* 归并排序合并函数
*/
void merge(int a[], int l, int m, int u)
{
int n1 = m - l + 1;
int n2 = u - m;
int left[n1], right[n2];
int i, j;
for (i = 0; i < n1; i++) /* left holds a[l..m] */
left[i] = a[l + i];
for (j = 0; j < n2; j++) /* right holds a[m+1..u] */
right[j] = a[m + 1 + j];
i = j = 0;
int k = l;
while (i < n1 && j < n2) {
if (left[i] < right[j])
a[k++] = left[i++];
else
a[k++] = right[j++];
}
while (i < n1) /* left[] is not exhausted */
a[k++] = left[i++];
while (j < n2) /* right[] is not exhausted */
a[k++] = right[j++];
}
/**
* 归并排序-非递归
*/
void mergeSortIter(int a[], int n)
{
int i, s=2;
while (s <= n) {
i = 0;
while (i+s <= n){
merge(a, i, i+s/2-1, i+s-1);
i += s;
}
//处理末尾残余部分
merge(a, i, i+s/2-1, n-1);
s*=2;
}
//最后再从头到尾处理一遍
merge(a, 0, s/2-1, n-1);
}
7 基数排序、桶排序
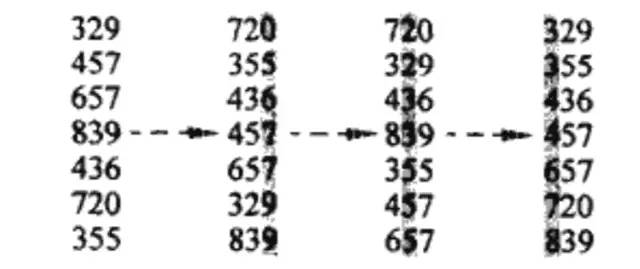
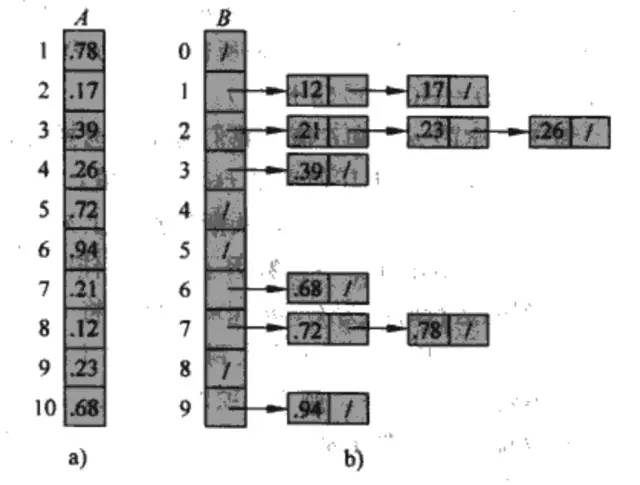
推荐阅读:
微信扫描二维码,关注我的公众号
朕已阅 
评论