
YOLObile:面向移动设备的「实时目标检测」算法
目标检测与深度学习
共 3892字,需浏览 8分钟
·
2021-03-27 14:52

1.1 Unstructured pruning
在搜寻最优的剪枝结构上有更好的灵活性 可以达到很高的模型压缩率和极低的精度丢失

1.2 Structured pruning
1.3 Pattern-based pruning
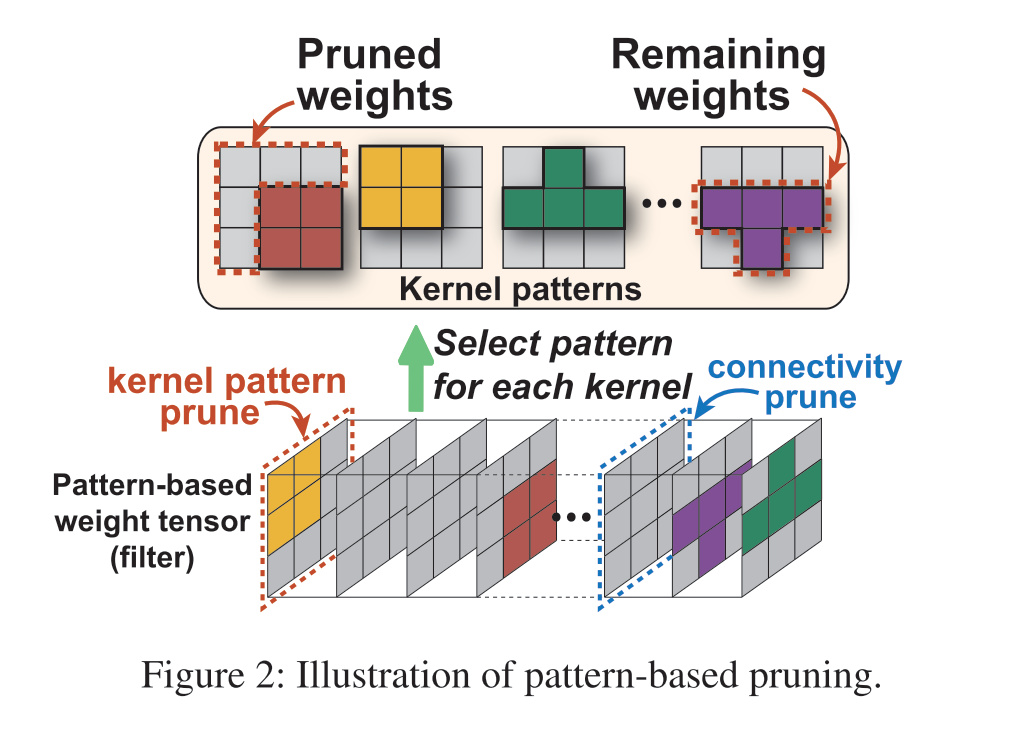
提出一种剪枝策略,可以同时保证速度和精度,并且可以推广到任意layer(pattern-based pruning只能应用在3x3卷积层) 提出一种更高效的计算加速策略
3.1 Block-punched pruning
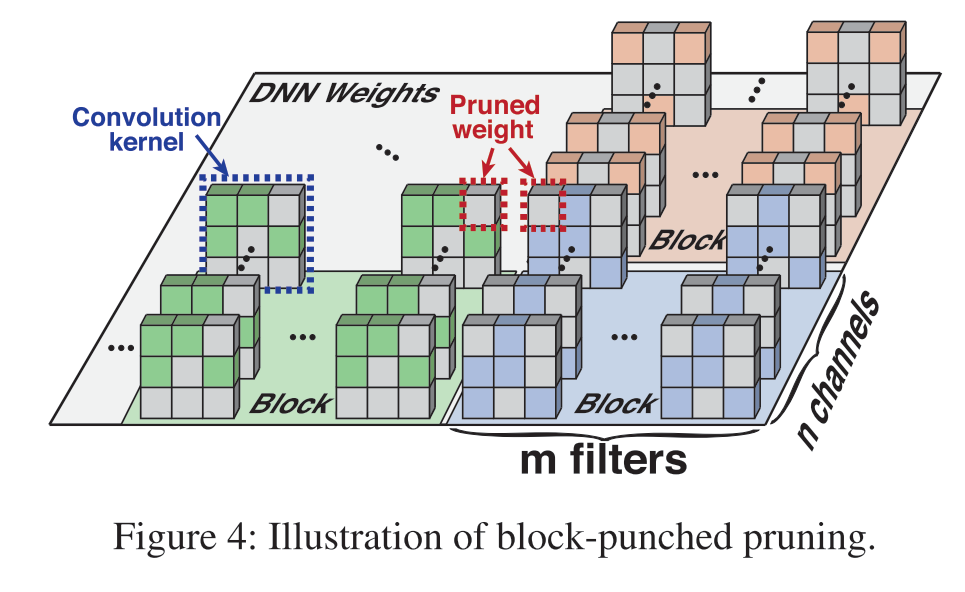
block size越小,精度丢失越少,但是推理速度也会变慢 block size越大,精度丢失越严重,但是推理速度变快
对于block中channel的数量:与设备中CPU/GPU的vector registers的长度一致 对于block中的filter的数量:在保证目标推理速度的前提下,选择最少的filter数量
3.2 Reweight regularization pruning algorithm
3.3 CPU-GPU合作机制
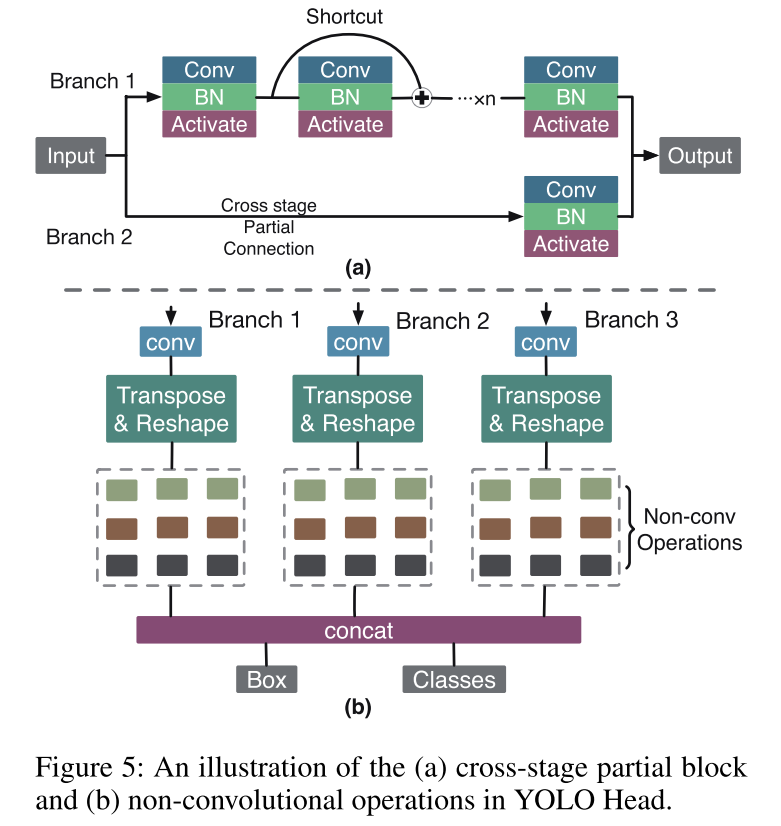
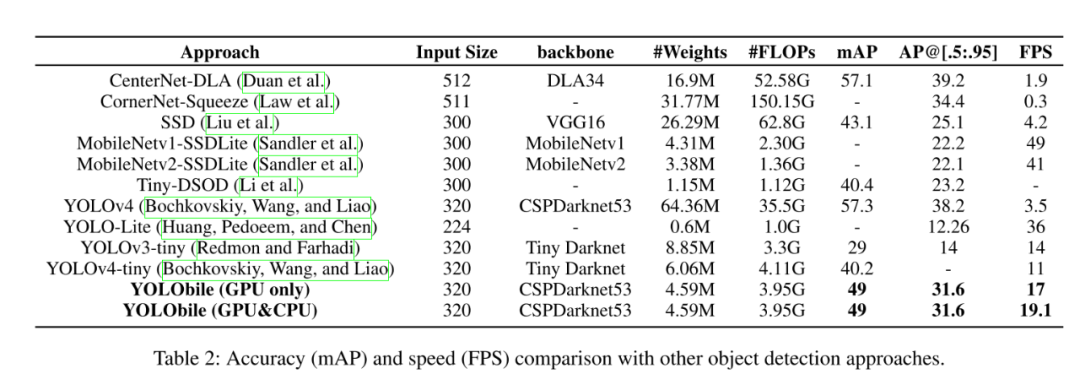
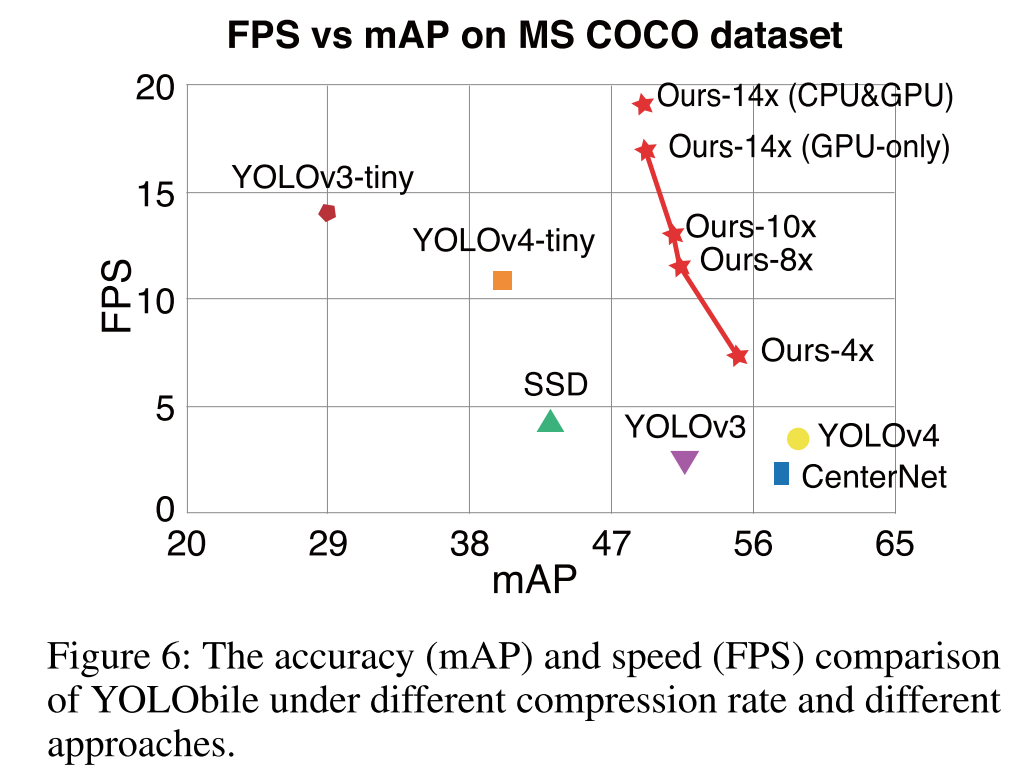
参考文献
✄------------------------------------------------
欢迎微信搜索并关注「目标检测与深度学习」,不被垃圾信息干扰,只分享有价值知识!
10000+人已加入目标检测与深度学习
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
敬正在努力的我们! 
评论