
收藏 | 可解释机器学习发展和常见方法!
程序员大白
共 2277字,需浏览 5分钟
·
2022-06-11 23:14
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

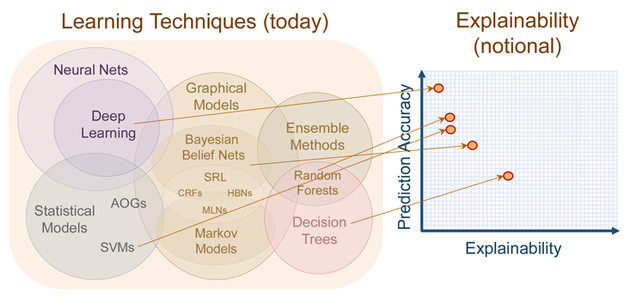
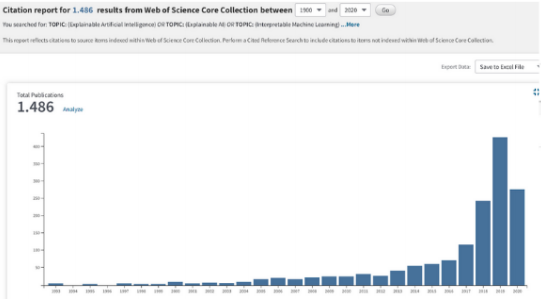
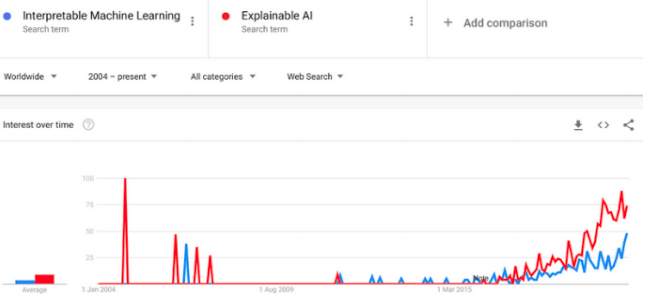
近年来,可解释机器学习(IML) 的相关研究蓬勃发展。尽管这个领域才刚刚起步,但是它在回归建模和基于规则的机器学习方面的相关工作却始于20世纪60年代。最近,arXiv上的一篇论文简要介绍了解释机器学习(IML)领域的历史,给出了最先进的可解释方法的概述,并讨论了遇到的挑战。
当机器学习模型用在产品、决策或者研究过程中的时候,“可解释性”通常是一个决定因素。
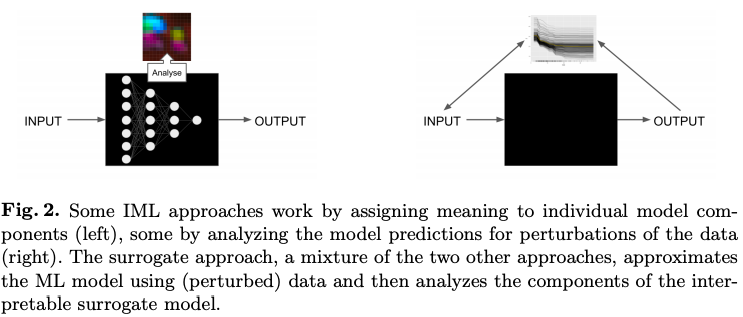
可解释机器学习(Interpretable machine learning ,简称 IML)可以用来来发现知识,调试、证明模型及其预测,以及控制和改进模型。
研究人员认为 IML的发展在某些情况下可以认为已经步入了一个新的阶段,但仍然存在一些挑战。
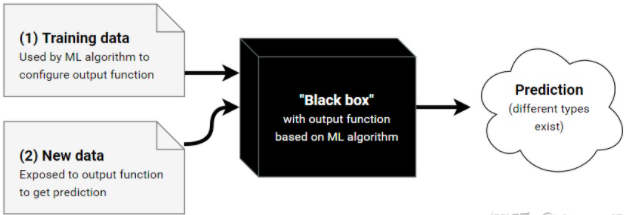
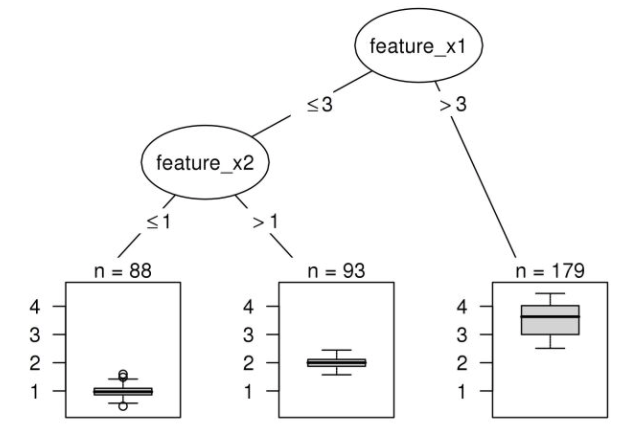
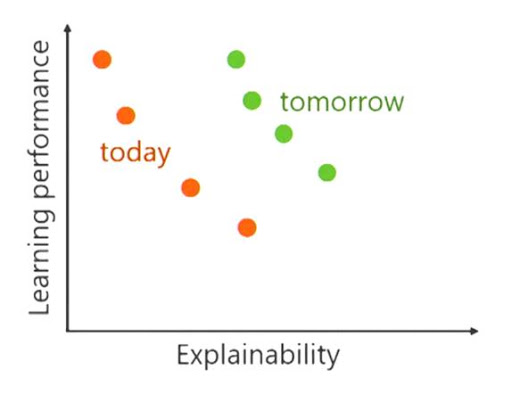
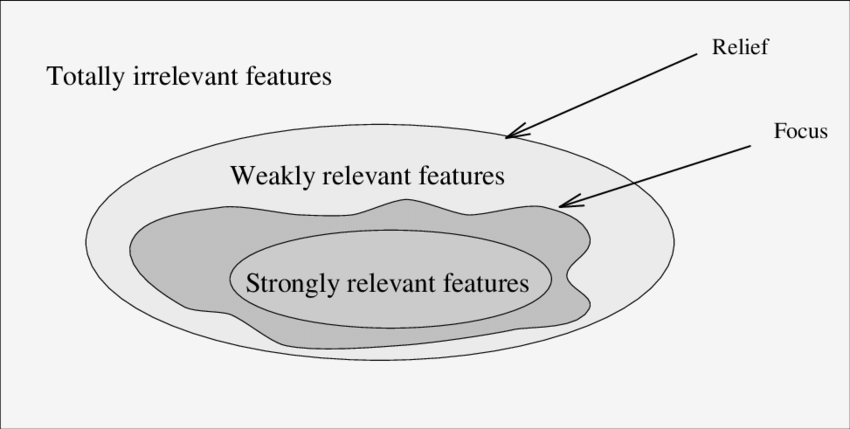
https://arxiv.org/abs/2010.09337
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论