
【Python机器学习案例】竟然很准!!Python预测淘宝2021双十一销售额
昨天双十一,大家对淘宝销售额感兴趣,自己做了个机器学习模型,竟然预测的挺准的。
数据链接:https://zh.wikipedia.org/wiki/%E5%8F%8C%E5%8D%81%E4%B8%80
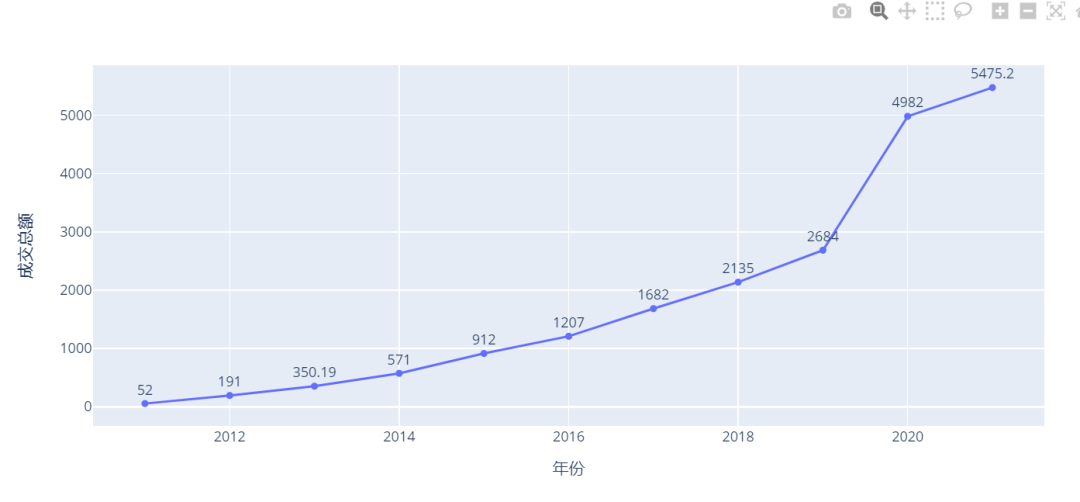
通过机器学习模型,预测今年的销售额是5475.2亿元
最终的新闻报告,是5403亿元,差的很少

下面是我的代码过程,代码地址:
https://gitee.com/antpython/ant-livebroadcast-publish
1、加载Excel数据
import pandas as pd
import numpy as np
df = pd.read_excel("./历史双十一销售额.xlsx")
df
年份 成交总额
0 2011 52.00
1 2012 191.00
2 2013 350.19
3 2014 571.00
4 2015 912.00
5 2016 1207.00
6 2017 1682.00
7 2018 2135.00
8 2019 2684.00
9 2020 4982.00
2、提取数据
x = np.array(df.iloc[:, 0]).reshape(-1, 1)
y = np.array(df.iloc[:, 1])
x.shape
(10, 1)
y.shape
(10,)
3、训练机器学习模型
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# 用管道的方式调用多项式回归算法
poly_reg = Pipeline([
('ploy', PolynomialFeatures(degree=2)),
('std_scaler', StandardScaler()),
('lin_reg', LinearRegression())
])
poly_reg.fit(x, y)
Pipeline(steps=[('ploy', PolynomialFeatures()),
('std_scaler', StandardScaler()),
('lin_reg', LinearRegression())])
# 算法评分
poly_reg.score(x, y)
0.9458618037222158
4、调用模型进行预测
current_year = 2021
predict = poly_reg.predict([[current_year]])
predict
array([5475.20483333])
5、绘制趋势图
df_new = df.append({"年份":"2021", "成交总额":predict[0]}, ignore_index=True)
df_new["成交总额"] = df_new["成交总额"].map(lambda x : round(x, 2))
df_new
年份 成交总额
0 2011 52.00
1 2012 191.00
2 2013 350.19
3 2014 571.00
4 2015 912.00
5 2016 1207.00
6 2017 1682.00
7 2018 2135.00
8 2019 2684.00
9 2020 4982.00
10 2021 5475.20
!pip install plotly
import plotly.express as px
fig = px.line(df_new, x="年份", y="成交总额", text="成交总额")
fig.update_traces(textposition="top center")
fig.show()
推荐下蚂蚁老师的机器学习课程
评论