
LeetCode刷题实战127:单词接龙
Given two words (beginWord and endWord), and a dictionary's word list, find the length of shortest transformation sequence from beginWord to endWord, such that:
Only one letter can be changed at a time.
Each transformed word must exist in the word list.
Note:
Return 0 if there is no such transformation sequence.
All words have the same length.
All words contain only lowercase alphabetic characters.
You may assume no duplicates in the word list.
You may assume beginWord and endWord are non-empty and are not the same.
题意
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典中的单词。
如果不存在这样的转换序列,返回 0。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
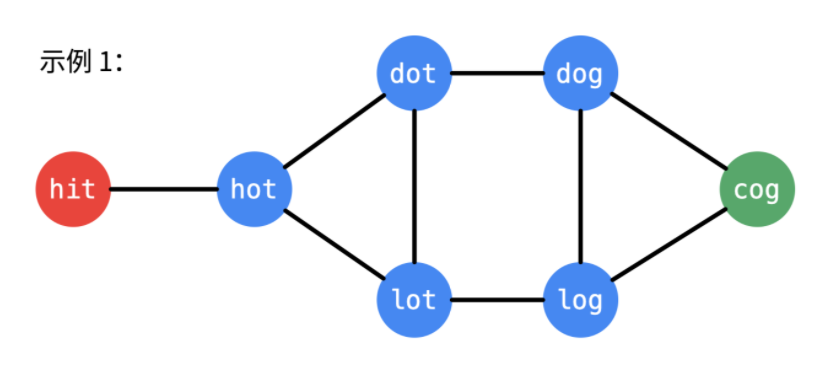
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出: 5
解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度 5。
示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: 0
解释: endWord "cog" 不在字典中,所以无法进行转换。
解题
队列;
visited 集合。说明:可以直接在 wordSet (由 wordList 放进集合中得到)里做删除。但更好的做法是新开一个哈希表,遍历过的字符串放进哈希表里。这种做法具有普遍意义。绝大多数在线测评系统和应用场景都不会在意空间开销。
方法一:广度优先遍历
public class Solution {
public int ladderLength(String beginWord, String endWord, ListwordList) {
// 第 1 步:先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
SetwordSet = new HashSet<>(wordList);
if (wordSet.size() == 0 || !wordSet.contains(endWord)) {
return 0;
}
wordSet.remove(beginWord);
// 第 2 步:图的广度优先遍历,必须使用队列和表示是否访问过的 visited 哈希表
Queuequeue = new LinkedList<>();
queue.offer(beginWord);
Setvisited = new HashSet<>();
visited.add(beginWord);
// 第 3 步:开始广度优先遍历,包含起点,因此初始化的时候步数为 1
int step = 1;
while (!queue.isEmpty()) {
int currentSize = queue.size();
for (int i = 0; i < currentSize; i++) {
// 依次遍历当前队列中的单词
String currentWord = queue.poll();
// 如果 currentWord 能够修改 1 个字符与 endWord 相同,则返回 step + 1
if (changeWordEveryOneLetter(currentWord, endWord, queue, visited, wordSet)) {
return step + 1;
}
}
step++;
}
return 0;
}
/**
* 尝试对 currentWord 修改每一个字符,看看是不是能与 endWord 匹配
*
* @param currentWord
* @param endWord
* @param queue
* @param visited
* @param wordSet
* @return
*/
private boolean changeWordEveryOneLetter(String currentWord, String endWord,
Queuequeue, Set {visited, Set wordSet)
char[] charArray = currentWord.toCharArray();
for (int i = 0; i < endWord.length(); i++) {
// 先保存,然后恢复
char originChar = charArray[i];
for (char k = 'a'; k <= 'z'; k++) {
if (k == originChar) {
continue;
}
charArray[i] = k;
String nextWord = String.valueOf(charArray);
if (wordSet.contains(nextWord)) {
if (nextWord.equals(endWord)) {
return true;
}
if (!visited.contains(nextWord)) {
queue.add(nextWord);
// 注意:添加到队列以后,必须马上标记为已经访问
visited.add(nextWord);
}
}
}
// 恢复
charArray[i] = originChar;
}
return false;
}
}
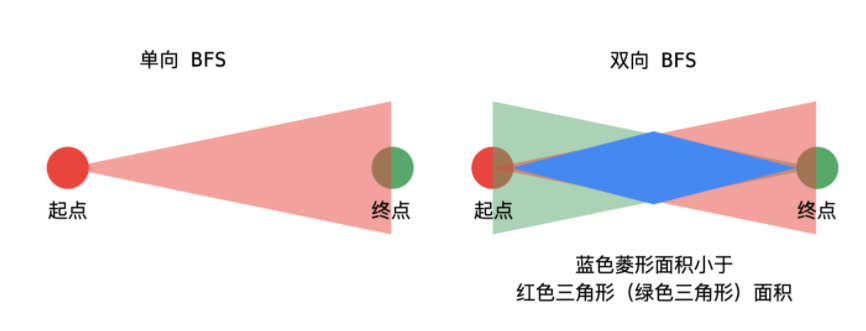
方法二:双向广度优先遍历
public class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 第 1 步:先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
Set<String> wordSet = new HashSet<>(wordList);
if (wordSet.size() == 0 || !wordSet.contains(endWord)) {
return 0;
}
// 第 2 步:已经访问过的 word 添加到 visited 哈希表里
Set<String> visited = new HashSet<>();
// 分别用左边和右边扩散的哈希表代替单向 BFS 里的队列,它们在双向 BFS 的过程中交替使用
Set<String> beginVisited = new HashSet<>();
beginVisited.add(beginWord);
Set<String> endVisited = new HashSet<>();
endVisited.add(endWord);
// 第 3 步:执行双向 BFS,左右交替扩散的步数之和为所求
int step = 1;
while (!beginVisited.isEmpty() && !endVisited.isEmpty()) {
// 优先选择小的哈希表进行扩散,考虑到的情况更少
if (beginVisited.size() > endVisited.size()) {
Set<String> temp = beginVisited;
beginVisited = endVisited;
endVisited = temp;
}
// 逻辑到这里,保证 beginVisited 是相对较小的集合,nextLevelVisited 在扩散完成以后,会成为新的 beginVisited
Set<String> nextLevelVisited = new HashSet<>();
for (String word : beginVisited) {
if (changeWordEveryOneLetter(word, endVisited, visited, wordSet, nextLevelVisited)) {
return step + 1;
}
}
// 原来的 beginVisited 废弃,从 nextLevelVisited 开始新的双向 BFS
beginVisited = nextLevelVisited;
step++;
}
return 0;
}
/**
* 尝试对 word 修改每一个字符,看看是不是能落在 endVisited 中,扩展得到的新的 word 添加到 nextLevelVisited 里
*
* @param word
* @param endVisited
* @param visited
* @param wordSet
* @param nextLevelVisited
* @return
*/
private boolean changeWordEveryOneLetter(String word, Set<String> endVisited,
Set<String> visited,
Set<String> wordSet,
Set<String> nextLevelVisited) {
char[] charArray = word.toCharArray();
for (int i = 0; i < word.length(); i++) {
char originChar = charArray[i];
for (char c = 'a'; c <= 'z'; c++) {
if (originChar == c) {
continue;
}
charArray[i] = c;
String nextWord = String.valueOf(charArray);
if (wordSet.contains(nextWord)) {
if (endVisited.contains(nextWord)) {
return true;
}
if (!visited.contains(nextWord)) {
nextLevelVisited.add(nextWord);
visited.add(nextWord);
}
}
}
// 恢复,下次再用
charArray[i] = originChar;
}
return false;
}
}