
ChatRWKV 学习笔记和使用指南
 在这里插入图片描述0x0. 前言
在这里插入图片描述0x0. 前言
Receptance Weighted Key Value(RWKV)是pengbo提出的一个新的语言模型架构,它使用了线性的注意力机制,把Transformer的高效并行训练与RNN的高效推理相结合,使得模型在训练期间可以并行,并在推理的时候保持恒定的计算和内存复杂度。目前RWKV的社区已经非常火了,我们从huggingface上可以看到RWKV已经训练了多个百亿参数的模型,特别是RWKV World模型支持世界所有语言的生成+对话+任务+代码,功能十分全面。此外还有很多开发者基于RWKV的微调模型。
 在部署方面RWKV社区也取得了长足的发展,例如ChatRWKV,rwkv.cpp,RWKV-Runner,rwkv-cpp-cuda,同时包括mlc-llm,tgi等都支持了RWKV相关模型,社区进展非常快。本文尝试从ChatRWKV项目入门学习一下RWKV。
在部署方面RWKV社区也取得了长足的发展,例如ChatRWKV,rwkv.cpp,RWKV-Runner,rwkv-cpp-cuda,同时包括mlc-llm,tgi等都支持了RWKV相关模型,社区进展非常快。本文尝试从ChatRWKV项目入门学习一下RWKV。
RWKV论文原文:https://arxiv.org/abs/2305.13048
0x1. 学习资料这里列出一些我看到的学习资料,方便感兴趣的读者学习:
- [双字] 在{Transformer}时代, {RWKV}是RNN的[文艺复兴]--论文详解(https://www.bilibili.com/video/BV11N411C76z/?spm_id_from=333.337.search-card.all.click&vd_source=4dffb0fbabed4311f4318e8c6d253a10)
- 野心勃勃的RNN——RWKV语言模型及其100行代码极简实现(https://zhuanlan.zhihu.com/p/620469303)
- github仓库(https://github.com/BlinkDL/RWKV-LM)
- rwkv论文原理解读(https://www.zhihu.com/question/602564718)
- RWKV的微调教学,以及RWKV World:支持世界所有语言的生成+对话+任务+代码(https://zhuanlan.zhihu.com/p/638326262)
- RWKV:用RNN达到Transformer性能,且支持并行模式和长程记忆,既快又省显存,已在14B参数规模检验(https://zhuanlan.zhihu.com/p/599150009)
- 谈谈 RWKV 系列的 prompt 设计,模型选择,解码参数设置(https://zhuanlan.zhihu.com/p/639629050)
- RWKV进展:一键生成论文,纯CPU高速INT4,纯CUDA脱离pytorch,ctx8192不耗显存不变慢(https://zhuanlan.zhihu.com/p/626083366)
- 开源1.5/3/7B中文小说模型:显存3G就能跑7B模型,几行代码即可调用(https://zhuanlan.zhihu.com/p/609154637)
- 发布几个RWKV的Chat模型(包括英文和中文)7B/14B欢迎大家玩(https://zhuanlan.zhihu.com/p/618011122)
- 实例:手写 CUDA 算子,让 Pytorch 提速 20 倍(某特殊算子)(https://zhuanlan.zhihu.com/p/476297195)
- BlinkDL/RWKV-World-7B gradio demo(https://huggingface.co/spaces/BlinkDL/RWKV-World-7B/tree/main)
- ChatRWKV(有可用猫娘模型!)微调/部署/使用/训练资源合集(https://zhuanlan.zhihu.com/p/616351661)
- pengbo的专栏(https://www.zhihu.com/people/bopengbopeng/posts)
原理推荐看第一个和第二个链接,其它的有选择观看,我这里就以ChatRWKV项目的解析为例来入门RWKV。
0x2. RWKV in 150 lines下面这个文件 https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py 以150行代码实现了RWKV-4-Pile-430M这个模型,是学习RWKV的最佳代码,所以让这一节就是来逐步解析一下这个代码。分析代码之前先对RWKV这个名字的含义和组成RWKV模型2个关键的元素Time Mixing和Channel Mixing简单描述一下,详细的原理还是请参考原始论文和第一节学习资料的第一个视频链接和第四个原理和公式详解的文字链接。
0x2.1 RWKV名字含义
论文中对名字有说明:
- R: Receptance vector acting as the acceptance of past information. 类似于LSTM的“门控单元”
- W: Weight is the positional weight decay vector. A trainable model parameter. 可学习的位置权重衰减向量,什么叫“位置权重衰减”看下面的公式(14)
- K: Key is a vector analogous to K in traditional attention. 与传统自注意力机制
- V : Value is a vector analogous to V in traditional attention. 与传统自注意力机制相同
0x2.2 RWKV模型架构
RWKV模型由一系列RWKV Block模块堆叠而成,RWKV Block的结构如下图所示: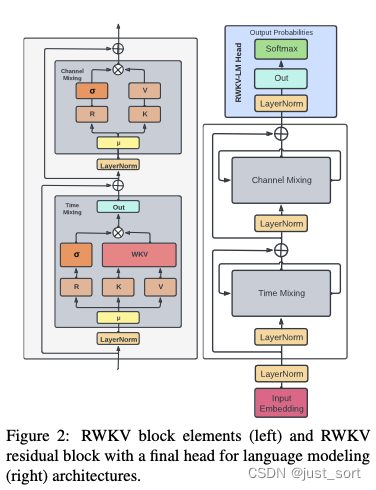
RWKV Block又主要由Time Mixing和Channel Mixing组成。
Time Mixing模块的公式定义如下:
这里的表示当前时刻,看成当前的token,而看成前一个token,、、的计算与传统Attention机制类似,通过将当前输入token与前一时刻输入token做线性插值,体现了recurrence的特性。然后的计算则是对应注意力机制的实现,这个实现也是一个过去时刻信息与当前时刻信息的线性插值,注意到这里是指数形式并且当前token和之前的所有token都有一个指数衰减求和的关系,也正是因为这样让拥有了线性attention的特性。
然后RWKV模型里面除了使用Time Mixing建模这种Token间的关系之外,在Token内对应的隐藏层维度上RWKV也进行了建模,即通过Channel Mixing模块。
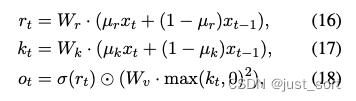 在这里插入图片描述
在这里插入图片描述
Channel Mixing的意思就是在特征维度上做融合。假设特征向量维度是d,那么每一个维度的元素都要接收其他维度的信息,来更新它自己。特征向量的每个维度就是一个“channel”(通道)。
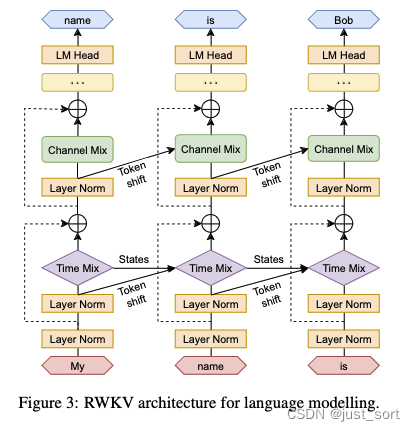
下图展示了RWKV模型整体的结构:
 在这里插入图片描述
在这里插入图片描述
这里提到的token shift就是上面对r, k, v计算的时候类似于卷积滑窗的过程。然后我们可以看到当前的token不仅仅剋呀通过Time Mixing的token shit和隐藏状态States(即)和之前的token建立联系,也可以通过Channel Mixing的token shift和之前的token建立联系,类似于拥有了全局感受野。
0x2.3 RWKV_in_150_lines.py 解析
初始化部分
首先来看RWKV模型初始化部分以及最开始的一些准备工作:
########################################################################################################
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
########################################################################################################
# 导入库
import numpy as np
# 这行代码设置了numpy数组的打印格式,其中precision=4表示小数点后保留4位,
# suppress=True表示抑制小数点的科学计数法表示,linewidth=200表示每行的字符宽度为200。
np.set_printoptions(precision=4, suppress=True, linewidth=200)
import types, torch
from torch.nn import functional as F
from tokenizers import Tokenizer
# 加载一个分词器
tokenizer = Tokenizer.from_file("20B_tokenizer.json")
# 使用types.SimpleNamespace()创建一个简单的命名空间对象args,并为其设置以下属性:
args = types.SimpleNamespace()
# 模型的路径。
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-430m/RWKV-4-Pile-430M-20220808-8066'
args.n_layer = 24 # 模型的层数。
args.n_embd = 1024 # 模型的嵌入维度。
# 定义了需要续写的字符串,描述了科学家在西藏的一个偏远山谷中发现了一群会说流利中文的龙的情况。
context = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
NUM_TRIALS = 3 # 尝试生成文本的次数。
LENGTH_PER_TRIAL = 100 # 每次尝试生成的文本长度。
TEMPERATURE = 1.0 # 控制生成文本的随机性的参数。值越大,生成的文本越随机;值越小,生成的文本越确定。
TOP_P = 0.85 # 在生成文本时,只考虑累积概率超过此值的词汇。
########################################################################################################
class RWKV_RNN(torch.jit.ScriptModule):
def __init__(self, args):
super().__init__()
# 将传入的args参数赋值给类的属性args。
self.args = args
# 将模型设置为评估模式,这意味着模型中的dropout和batchnorm将被禁用。
self.eval() # set torch to inference mode
# 从指定路径加载模型权重,并确保权重被加载到CPU上。
w = torch.load(args.MODEL_NAME + '.pth', map_location='cpu')
# 这几行代码对加载的权重进行了处理。它们检查权重的键名,并根据键名对权重进行不同的操作。
for k in w.keys():
if '.time_' in k: w[k] = w[k].squeeze()
if '.time_decay' in k: w[k] = -torch.exp(w[k].float()) # the real time decay is like e^{-e^x}
else: w[k] = w[k].float() # convert to f32 type
# 创建一个新的命名空间对象,并将其赋值给self.w。
self.w = types.SimpleNamespace() # set self.w from w
# 在self.w中创建一个名为blocks的字典。
self.w.blocks = {}
# for k in w.keys(): - 遍历字典w的所有键。注释中的例子
# "blocks.0.att.time_first" => self.w.blocks[0].att.time_first"
# 说明了代码的目标:将点分隔的键转换为嵌套的属性访问。
for k in w.keys(): # example: "blocks.0.att.time_first" => self.w.blocks[0].att.time_first
parts = k.split('.') # 使用.作为分隔符将键k分割成多个部分,并将结果存储在parts列表中。
last = parts.pop() # 从parts列表中弹出最后一个元素并存储在last中。这将是要设置的属性的名称。
# 初始化一个变量here,它将用于遍历或创建self.w中的嵌套命名空间。
here = self.w
# 遍历parts列表中的每个部分。
for p in parts:
# 检查当前部分p是否是数字。
if p.isdigit():
p = int(p)
# 如果当前数字键p不在here中,则在here中为其创建一个新的命名空间。
if p not in here: here[p] = types.SimpleNamespace()
# 更新here以指向新创建的或已存在的命名空间。
here = here[p]
# 如果当前部分p不是数字。
else:
# 如果here没有名为p的属性,则为其创建一个新的命名空间。
if not hasattr(here, p): setattr(here, p, types.SimpleNamespace())
here = getattr(here, p)
setattr(here, last, w[k])
这部分除了准备一些模型执行需要的超参数之外,还对RWKV模型进行了初始化,值得注意的是在初始化过程中会加载RWKV模型的权重到w这个字典里面,然后遍历字典w的所有键。注释中的例子"blocks.0.att.time_first" => self.w.blocks[0].att.time_first" 说明了代码的目标:将点分隔的键转换为嵌套的属性访问。后面推理的时候将会直接访问self.w这个处理之后的权重对象。
RWKV 模型通道融合函数(Channel mixing)
@torch.jit.script_method
def channel_mixing(self, x, state, i:int, time_mix_k, time_mix_r, kw, vw, rw):
xk = x * time_mix_k + state[5*i+0] * (1 - time_mix_k)
xr = x * time_mix_r + state[5*i+0] * (1 - time_mix_r)
state[5*i+0] = x
r = torch.sigmoid(rw @ xr)
k = torch.square(torch.relu(kw @ xk)) # square relu, primer paper
return r * (vw @ k)
参考Channel Mixing的公式来看:
在这里插入图片描述
在channel_mixing函数里面,对应当前token的词嵌入向量,表示前一个token的词嵌入向量。剩下的变量都是RWKV的可学习参数。然后代码里面会动态更新state,让总是当前token的前一个token的词嵌入。
RWKV Time mixing函数
@torch.jit.script_method
def time_mixing(self, x, state, i:int, time_mix_k, time_mix_v, time_mix_r, time_first, time_decay, kw, vw, rw, ow):
xk = x * time_mix_k + state[5*i+1] * (1 - time_mix_k)
xv = x * time_mix_v + state[5*i+1] * (1 - time_mix_v)
xr = x * time_mix_r + state[5*i+1] * (1 - time_mix_r)
state[5*i+1] = x
r = torch.sigmoid(rw @ xr)
k = kw @ xk
v = vw @ xv
aa = state[5*i+2]
bb = state[5*i+3]
pp = state[5*i+4]
ww = time_first + k
qq = torch.maximum(pp, ww)
e1 = torch.exp(pp - qq)
e2 = torch.exp(ww - qq)
a = e1 * aa + e2 * v
b = e1 * bb + e2
wkv = a / b
ww = pp + time_decay
qq = torch.maximum(ww, k)
e1 = torch.exp(ww - qq)
e2 = torch.exp(k - qq)
state[5*i+2] = e1 * aa + e2 * v
state[5*i+3] = e1 * bb + e2
state[5*i+4] = qq
return ow @ (r * wkv)
仍然是要对照公式来看:
然后这里有一个trick,就是对的计算可以写成RNN的递归形式: 这样上面的公式就很清晰了,还需要注意的是在实现的时候由于有exp的存在,为了保证数值稳定性实现的时候减去了每个公式涉及到的e的指数部分的Max。
这样上面的公式就很清晰了,还需要注意的是在实现的时候由于有exp的存在,为了保证数值稳定性实现的时候减去了每个公式涉及到的e的指数部分的Max。
关于RWKV 的attention部分()计算如果你有细节不清楚,建议观看一下这个视频:解密RWKV线性注意力的进化过程(https://www.bilibili.com/video/BV1zW4y1D7Qg/?spm_id_from=333.337.search-card.all.click&vd_source=4dffb0fbabed4311f4318e8c6d253a10) 。
RWKV model forward函数
# 定义forward方法,它接受两个参数:token和state。
def forward(self, token, state):
# 这是一个上下文管理器,确保在此代码块中不会计算任何梯度。
# 这通常用于评估模式,以提高性能并避免不必要的计算。
with torch.no_grad():
# 如果state为None,则初始化state为一个全零张量。
# 其形状由self.args.n_layer和self.args.n_embd确定。
if state == None:
state = torch.zeros(self.args.n_layer * 5, self.args.n_embd)
# 遍历每一层,并将state的特定位置设置为-1e30(表示负无穷大)。
for i in range(self.args.n_layer): state[5*i+4] = -1e30 # -infinity
# 使用token索引self.w.emb.weight,获取词嵌入向量。
x = self.w.emb.weight[token]
# 对获取的词嵌入向量x应用层归一化。
x = self.layer_norm(x, self.w.blocks[0].ln0)
for i in range(self.args.n_layer):
att = self.w.blocks[i].att # 获取当前层的注意力参数
# 这些行使用time_mixing方法对x进行处理,并将结果加到x上。
x = x + self.time_mixing(self.layer_norm(x, self.w.blocks[i].ln1), state, i,
att.time_mix_k, att.time_mix_v, att.time_mix_r, att.time_first, att.time_decay,
att.key.weight, att.value.weight, att.receptance.weight, att.output.weight)
ffn = self.w.blocks[i].ffn # 获取当前层的前馈网络参数。
# 使用channel_mixing方法对x进行处理,并将结果加到x上。
x = x + self.channel_mixing(self.layer_norm(x, self.w.blocks[i].ln2), state, i,
ffn.time_mix_k, ffn.time_mix_r,
ffn.key.weight, ffn.value.weight, ffn.receptance.weight)
# 对x应用最后的层归一化,并与self.w.head.weight进行矩阵乘法。
x = self.w.head.weight @ self.layer_norm(x, self.w.ln_out)
return x.float(), state
从这里可以看到RWKV的state只和层数和嵌入层维度有关系,和序列长度是无关的,这是推理时相比于RNN的核心优点。
采样函数
# 这段代码是一个用于生成随机样本的函数。
# 这是一个函数定义,函数名为 sample_logits,接受三个参数 out、temperature
# 和 top_p,其中 temperature 默认值为 1.0,top_p 默认值为 0.8。
def sample_logits(out, temperature=1.0, top_p=0.8):
# 这行代码使用 softmax 函数对 out 进行操作,将输出转换为概率分布。
# dim=-1 表示在最后一个维度上进行 softmax 操作。.numpy() 将结果转换为 NumPy 数组。
probs = F.softmax(out, dim=-1).numpy()
# 这行代码使用 NumPy 的 np.sort 函数对概率分布进行排序,
# 并通过 [::-1] 实现降序排列。结果保存在 sorted_probs 变量中。
sorted_probs = np.sort(probs)[::-1]
# 这行代码计算累积概率,使用 NumPy 的 np.cumsum 函数对 sorted_probs
# 进行累加操作。结果保存在 cumulative_probs 变量中。
cumulative_probs = np.cumsum(sorted_probs)
# 这行代码通过比较 cumulative_probs 是否大于 top_p 来找到概率分布中的截断点。
# np.argmax 返回第一个满足条件的索引,float() 将其转换为浮点数并保存在 cutoff 变量中。
cutoff = float(sorted_probs[np.argmax(cumulative_probs > top_p)])
# 这行代码将低于 cutoff 的概率值设为 0,即将概率分布中小于截断点的概率置零。
probs[probs < cutoff] = 0
# 这段代码根据 temperature 的取值对概率分布进行调整。
# 如果 temperature 不等于 1.0,则将概率分布的每个元素取倒数的 1.0 / temperature 次幂。
if temperature != 1.0:
probs = probs.pow(1.0 / temperature)
# 这行代码将概率分布归一化,确保所有概率的总和为 1。
probs = probs / np.sum(probs)
# 这行代码使用 np.random.choice 函数根据概率分布 probs 生成一个随机样本,
# a=len(probs) 表示可选的样本范围为 probs 的长度,p=probs 表示每个样本被选中的概率。
out = np.random.choice(a=len(probs), p=probs)
# 函数返回生成的随机样本。
return out
这个函数的作用是根据给定的概率分布 out 生成一个随机样本,通过调整温度 temperature 和顶部概率 top_p 来控制生成的样本的多样性和稳定性。
生成文本的流程
# 打印使用 CPU 加载模型的信息,其中 args.MODEL_NAME 是模型名称。
print(f'\nUsing CPU. Loading {args.MODEL_NAME} ...')
# 创建一个名为 model 的 RWKV_RNN 模型实例,参数为 args。
model = RWKV_RNN(args)
# 打印预处理上下文信息的提示,提示使用的是较慢的版本。然后初始化 init_state 为 None。
print(f'\nPreprocessing context (slow version. see v2/rwkv/model.py for fast version)')
init_state = None
# 对上下文进行分词编码,并使用模型的 forward 方法逐个处理分词编码的 tokens,
# 将结果保存在 init_out 和 init_state 中。
for token in tokenizer.encode(context).ids:
init_out, init_state = model.forward(token, init_state)
# 使用循环进行多次试验(NUM_TRIALS 次)。
for TRIAL in range(NUM_TRIALS):
# 在每次试验的开始打印试验信息和上下文。创建一个空列表 all_tokens 用于保存生成的 tokens。
print(f'\n\n--[ Trial {TRIAL} ]-----------------', context, end="")
all_tokens = []
# 初始化变量 out_last 为 0,out 和 state 分别为 init_out 和 init_state 的克隆。
out_last = 0
out, state = init_out.clone(), init_state.clone()
# 在每个试验中,使用循环生成 LENGTH_PER_TRIAL 个 tokens。
for i in range(LENGTH_PER_TRIAL):
# 调用 sample_logits 函数生成一个随机 token,并将其添加到 all_tokens 列表中。
token = sample_logits(out, TEMPERATURE, TOP_P)
all_tokens += [token]
# 使用 tokenizer.decode 将 all_tokens[out_last:] 解码为文本,
# 并检查解码结果是否包含无效的 utf-8 字符('\ufffd')。如果结果有效,则将其打印出来。
tmp = tokenizer.decode(all_tokens[out_last:])
if '\ufffd' not in tmp: # only print when we have a valid utf-8 string
print(tmp, end="", flush=True)
out_last = i + 1
# 调用模型的 forward 方法,将生成的 token 和当前的状态传递给模型,获取更新的 out 和 state。
out, state = model.forward(token, state)
print('\n')
这段代码的目的是使用 RWKV_RNN 模型生成文本,模型通过 sample_logits 函数生成随机 token,然后将其传递给模型进行预测,并根据预测结果生成下一个 token,不断重复这个过程直到生成指定数量的 tokens。生成的文本会被打印出来。
0x3. ChatRWKV v2聊天系统逻辑实现解析ChatRWKV的README中提到v2版本实现了一些新功能,建议我们使用,v2版本的代码在 https://github.com/BlinkDL/ChatRWKV/tree/main/v2 。我们这一节就对这部分的代码做一个解读。
chat.py解析
https://github.com/BlinkDL/ChatRWKV/blob/main/v2/chat.py是ChatRWKV v2的核心实现,我们直接来看这个文件。
########################################################################################################
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
########################################################################################################
# os、copy、types、gc、sys:这些是Python标准库,
# 用于操作系统功能、对象复制、类型管理、垃圾回收和系统特定的参数和函数。
import os, copy, types, gc, sys
current_path = os.path.dirname(os.path.abspath(__file__))
sys.path.append(f'{current_path}/../rwkv_pip_package/src')
import numpy as np
# prompt_toolkit中的prompt:用于构建命令行界面的库。
from prompt_toolkit import prompt
# 脚本尝试根据传递给脚本的命令行参数设置CUDA_VISIBLE_DEVICES环境变量。
try:
os.environ["CUDA_VISIBLE_DEVICES"] = sys.argv[1]
except:
pass
# 调用np.set_printoptions()函数设置NumPy数组的打印选项。它配置精度、抑制小值和输出行的最大宽度。
np.set_printoptions(precision=4, suppress=True, linewidth=200)
args = types.SimpleNamespace()
# 脚本打印有关ChatRWKV版本的信息。
print('\n\nChatRWKV v2 https://github.com/BlinkDL/ChatRWKV')
import torch
# 针对PyTorch设置了几个配置,以优化其在GPU上的性能。
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
# 有一些被注释的行代表不同的设置,可以尝试优化性能。这些设置与PyTorch的即时编译(JIT)和融合有关。
# Tune these below (test True/False for all of them) to find the fastest setting:
# torch._C._jit_set_profiling_executor(True)
# torch._C._jit_set_profiling_mode(True)
# torch._C._jit_override_can_fuse_on_cpu(True)
# torch._C._jit_override_can_fuse_on_gpu(True)
# torch._C._jit_set_texpr_fuser_enabled(False)
# torch._C._jit_set_nvfuser_enabled(False)
########################################################################################################
#
# 有一些注释解释了不同的模型精度选项(fp16、fp32、bf16、xxxi8)及其影响。
# fp16 = good for GPU (!!! DOES NOT support CPU !!!)
# fp32 = good for CPU
# bf16 = less accuracy, supports some CPUs
# xxxi8 (example: fp16i8) = xxx with int8 quantization to save 50% VRAM/RAM, slightly less accuracy
#
# Read https://pypi.org/project/rwkv/ for Strategy Guide
#
########################################################################################################
这段代码设置了必要的依赖项,配置了GPU使用环境,并提供了有关RWKV语言模型及其精度选项的信息。
# 这个变量用于设置模型推理的策略。在代码中有几个不同的策略选项被注释掉了,
# 而实际选择的策略是 'cuda fp16',表示使用CUDA加速并使用半精度浮点数进行计算。
# args.strategy = 'cpu fp32'
args.strategy = 'cuda fp16'
# args.strategy = 'cuda:0 fp16 -> cuda:1 fp16'
# args.strategy = 'cuda fp16i8 *10 -> cuda fp16'
# args.strategy = 'cuda fp16i8'
# args.strategy = 'cuda fp16i8 -> cpu fp32 *10'
# args.strategy = 'cuda fp16i8 *10+'
# 这两个变量设置了环境变量。RWKV_JIT_ON 控制是否启用即时编译(JIT),
# RWKV_CUDA_ON 控制是否编译CUDA内核。在代码中,RWKV_CUDA_ON 被设置为0,即不编译CUDA内核。
os.environ["RWKV_JIT_ON"] = '1' # '1' or '0', please use torch 1.13+ and benchmark speed
os.environ["RWKV_CUDA_ON"] = '0' # '1' to compile CUDA kernel (10x faster), requires c++ compiler & cuda libraries
# 这个变量设置了聊天系统使用的语言,可以选择英语('English')、中文('Chinese')或日语('Japanese')。
CHAT_LANG = 'English' # English // Chinese // more to come
# 这个变量设置了模型的名称和路径。根据选择的语言不同,会有不同的模型名称被设置。
# 模型名称指定了模型文件的位置,以及其他一些相关信息。
# Download RWKV models from https://huggingface.co/BlinkDL
# Use '/' in model path, instead of '\'
# Use convert_model.py to convert a model for a strategy, for faster loading & saves CPU RAM
if CHAT_LANG == 'English':
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v12-Eng98%-Other2%-20230523-ctx8192'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-14b/RWKV-4-Pile-14B-20230313-ctx8192-test1050'
elif CHAT_LANG == 'Chinese': # Raven系列可以对话和 +i 问答。Novel系列是小说模型,请只用 +gen 指令续写。
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-novel/RWKV-4-Novel-7B-v1-ChnEng-20230426-ctx8192'
elif CHAT_LANG == 'Japanese':
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v8-EngAndMore-20230408-ctx4096'
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v10-Eng89%-Jpn10%-Other1%-20230420-ctx4096'
# -1.py for [User & Bot] (Q&A) prompt
# -2.py for [Bob & Alice] (chat) prompt
# 这个变量设置了模型的名称和路径。根据选择的语言不同,会有不同的模型名称被设置。
# 模型名称指定了模型文件的位置,以及其他一些相关信息。
PROMPT_FILE = f'{current_path}/prompt/default/{CHAT_LANG}-2.py'
# 代码中还包含了一些其他参数的设置,如聊天长度的限制、生成文本的参数(温度、top-p值等)、重复惩罚等。
CHAT_LEN_SHORT = 40
CHAT_LEN_LONG = 150
FREE_GEN_LEN = 256
# For better chat & QA quality: reduce temp, reduce top-p, increase repetition penalties
# Explanation: https://platform.openai.com/docs/api-reference/parameter-details
# 这个变量用于控制生成文本的温度。通过调整温度值,可以控制生成文本的随机性和多样性。
# 在代码中设置为1.2,表示较高的温度,可以增加生成文本的多样性。
GEN_TEMP = 1.2 # It could be a good idea to increase temp when top_p is low
# 这个变量用于控制生成文本的top-p值。Top-p是一种生成文本的策略,
# 它限制了生成文本中概率最高的单词的累积概率。
# 通过减小top-p值,可以提高生成文本的准确性和一致性。在代码中设置为0.5,表示较低的top-p值。
GEN_TOP_P = 0.5 # Reduce top_p (to 0.5, 0.2, 0.1 etc.) for better Q&A accuracy (and less diversity)
# 这两个变量分别控制生成文本中重复内容的惩罚权重。
# GEN_alpha_presence 控制了存在性惩罚的权重,即生成文本中重复内容的惩罚程度。
# GEN_alpha_frequency 控制了频率惩罚的权重,即生成文本中连续重复内容的惩罚程度。
# 在代码中,它们都被设置为0.4。
GEN_alpha_presence = 0.4 # Presence Penalty
GEN_alpha_frequency = 0.4 # Frequency Penalty
# 这个变量控制了重复惩罚的衰减率。通过减小衰减率,可以使重复惩罚在生成文本的后续部分逐渐减弱。
# 在代码中设置为0.996。
GEN_penalty_decay = 0.996
# 这个变量设置了一些标点符号,用于表示要避免在生成文本中重复的内容。
# 在代码中,它包含了中文的逗号、冒号、问号和感叹号。
AVOID_REPEAT = ',:?!'
# 这个变量用于将输入分成多个块,以节省显存(VRAM)。在代码中设置为256。
CHUNK_LEN = 256 # split input into chunks to save VRAM (shorter -> slower)
# 这个变量包含了模型的名称和路径。根据代码中的注释,可以看到有几个不同的模型路径被设置。
# 根据具体情况,会选择其中一个模型路径。
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-CHNtuned-0.1B-v1-20230617-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-CHNtuned-0.4B-v1-20230618-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-3B-v1-20230619-ctx4096'
if args.MODEL_NAME.endswith('/'): # for my own usage
if 'rwkv-final.pth' in os.listdir(args.MODEL_NAME):
args.MODEL_NAME = args.MODEL_NAME + 'rwkv-final.pth'
else:
latest_file = sorted([x for x in os.listdir(args.MODEL_NAME) if x.endswith('.pth')], key=lambda x: os.path.getctime(os.path.join(args.MODEL_NAME, x)))[-1]
args.MODEL_NAME = args.MODEL_NAME + latest_file
这段代码相当于配置文件,来设置RWKV聊天系统的运行参数和模型信息。根据选择的语言不同,会加载相应的模型,并设置相应的参数。
########################################################################################################
# 这行代码用于打印一个字符串,包含了 CHAT_LANG、args.strategy 和 PROMPT_FILE 的值。
# 它会在控制台输出当前的语言、策略和提示文件的信息。
print(f'\n{CHAT_LANG} - {args.strategy} - {PROMPT_FILE}')
# 导入 RWKV 模型
from rwkv.model import RWKV
# 这行代码导入了 PIPELINE 工具,用于处理模型的输入和输出。
from rwkv.utils import PIPELINE
# 用于加载提示文件的内容并返回相应的变量。
def load_prompt(PROMPT_FILE):
# 该函数首先创建了一个空的字典 variables,然后使用 open 函数打开 PROMPT_FILE 文件。
variables = {}
# 下来,使用 exec 函数将文件内容编译并执行,将结果存储在 variables 字典中。
with open(PROMPT_FILE, 'rb') as file:
exec(compile(file.read(), PROMPT_FILE, 'exec'), variables)
# 然后,从 variables 字典中获取了 user、bot、interface 和 init_prompt 的值。
# init_prompt 被处理为一个列表,去除了多余的空格和换行符,并在开头和结尾添加了换行符。
# 最后,函数返回获取的变量。
user, bot, interface, init_prompt = variables['user'], variables['bot'], variables['interface'], variables['init_prompt']
init_prompt = init_prompt.strip().split('\n')
for c in range(len(init_prompt)):
init_prompt[c] = init_prompt[c].strip().strip('\u3000').strip('\r')
init_prompt = '\n' + ('\n'.join(init_prompt)).strip() + '\n\n'
return user, bot, interface, init_prompt
# Load Model
# 这行代码用于打印一个字符串,指示正在加载模型,并输出 args.MODEL_NAME 的值。
print(f'Loading model - {args.MODEL_NAME}')
# 这行代码创建了一个 RWKV 模型对象,使用指定的模型路径 args.MODEL_NAME 和策略 args.strategy。
model = RWKV(model=args.MODEL_NAME, strategy=args.strategy)
# 根据 args.MODEL_NAME 的值,选择了不同的分词器和特殊标记。
# 如果模型路径中包含 'world/' 或 '-World-',则使用 "rwkv_vocab_v20230424" 的分词器,
# 并设置了 END_OF_TEXT 和 END_OF_LINE 的值。
# 否则,使用 current_path(当前路径)和 "20B_tokenizer.json" 的分词器,
# 并设置了 END_OF_TEXT、END_OF_LINE 和 END_OF_LINE_DOUBLE 的值。
if 'world/' in args.MODEL_NAME or '-World-' in args.MODEL_NAME:
pipeline = PIPELINE(model, "rwkv_vocab_v20230424")
END_OF_TEXT = 0
END_OF_LINE = 11
else:
pipeline = PIPELINE(model, f"{current_path}/20B_tokenizer.json")
END_OF_TEXT = 0
END_OF_LINE = 187
END_OF_LINE_DOUBLE = 535
# pipeline = PIPELINE(model, "cl100k_base")
# END_OF_TEXT = 100257
# END_OF_LINE = 198
# 这行代码创建了一个空的列表 model_tokens,用于存储模型的输入token。
model_tokens = []
model_state = None
# 这行代码创建了一个空的列表 AVOID_REPEAT_TOKENS,用于存储避免重复的标记。
AVOID_REPEAT_TOKENS = []
for i in AVOID_REPEAT:
# 在循环内部,将当前元素 i 使用 pipeline.encode 函数进行编码,
# 并将结果添加到 AVOID_REPEAT_TOKENS 列表中。
# 这样,AVOID_REPEAT_TOKENS 列表中存储了避免重复的token的编码。
dd = pipeline.encode(i)
assert len(dd) == 1
AVOID_REPEAT_TOKENS += dd
这段代码的主要功能是加载和配置RWKV模型,并准备生成文本所需的参数和工具。继续解析:
########################################################################################################
# 这是一个函数定义,用于以RNN模式运行RWKV模型生成文本。
def run_rnn(tokens, newline_adj = 0):
# 这行代码声明在函数内部使用全局变量 model_tokens 和 model_state。
global model_tokens, model_state
# 将输入的token列表转换为整数类型。
tokens = [int(x) for x in tokens]
# 将输入的标记列表添加到全局变量 model_tokens 中。
model_tokens += tokens
# print(f'### model ###\n{tokens}\n[{pipeline.decode(model_tokens)}]')
# 当token列表的长度大于0时,执行以下操作:
while len(tokens) > 0:
# 使用模型的前向传播函数 model.forward 对token列表的前
# CHUNK_LEN 个token进行推理,并更新模型状态。
out, model_state = model.forward(tokens[:CHUNK_LEN], model_state)
# 将token列表更新为剩余的token。
tokens = tokens[CHUNK_LEN:]
# 将输出概率向量中的换行符标记 END_OF_LINE 的概率增加 newline_adj,用于调整换行的概率。
out[END_OF_LINE] += newline_adj # adjust \n probability
# 如果模型最后一个标记在避免重复标记列表 AVOID_REPEAT_TOKENS 中,执行以下操作:
if model_tokens[-1] in AVOID_REPEAT_TOKENS:
# 将输出概率向量中模型最后一个标记对应的概率设置为一个极小的值,用于避免模型生成重复的标记。
out[model_tokens[-1]] = -999999999
return out
all_state = {}
# 这是一个函数定义,用于保存模型状态和token列表。
def save_all_stat(srv, name, last_out):
# 创建保存状态的键名。
n = f'{name}_{srv}'
all_state[n] = {} # 创建一个空的字典,用于保存模型状态和token列表。
all_state[n]['out'] = last_out # 将最后的输出概率向量保存到字典中。
all_state[n]['rnn'] = copy.deepcopy(model_state) # 将深拷贝后的模型状态保存到字典中。
all_state[n]['token'] = copy.deepcopy(model_tokens) # 将深拷贝后的token列表保存到字典中。
# 这是一个函数定义,用于加载保存的模型状态和标记列表。
def load_all_stat(srv, name):
# 这行代码声明在函数内部使用全局变量 model_tokens 和 model_state。
global model_tokens, model_state
# 获取保存状态的键名。
n = f'{name}_{srv}'
# 将保存的模型状态深拷贝给全局变量 model_state。
model_state = copy.deepcopy(all_state[n]['rnn'])
# 将保存的token列表深拷贝给全局变量 model_tokens。
model_tokens = copy.deepcopy(all_state[n]['token'])
return all_state[n]['out']
# Model only saw '\n\n' as [187, 187] before, but the tokenizer outputs [535] for it at the end
# 这是一个函数定义,用于修复token列表。
def fix_tokens(tokens):
# 根据模型路径是否包含 'world/' 或 '-World-',执行以下操作:
if 'world/' in args.MODEL_NAME or '-World-' in args.MODEL_NAME:
# 如果是,则返回原始的标记列表 tokens,无需修复。
return tokens
# 如果不是,则检查标记列表的最后一个标记是否为 END_OF_LINE_DOUBLE,
# 如果是,则将标记列表中的最后一个标记替换为 END_OF_LINE 重复两次。
if len(tokens) > 0 and tokens[-1] == END_OF_LINE_DOUBLE:
tokens = tokens[:-1] + [END_OF_LINE, END_OF_LINE]
return tokens
########################################################################################################
这段代码定义了以RNN模式运行RWKV的函数以及保存和恢复模型状态的函数,最后还定义了一个修复tokens的工具函数用于对world模型和其它模型分别进行处理,继续解析:
########################################################################################################
# Run inference
print(f'\nRun prompt...') # 打印提示信息 "Run prompt..."。
# 调用 load_prompt 函数加载提示文件,将返回的用户、机器人、界面和初始提示内容
# 分别赋值给变量 user、bot、interface 和 init_prompt。
user, bot, interface, init_prompt = load_prompt(PROMPT_FILE)
# 调用 fix_tokens 函数修复初始提示内容的标记列表,并将修复后的标记列表传递给 run_rnn 函数进行推理。
# 将生成的输出概率向量赋值给变量 out。
out = run_rnn(fix_tokens(pipeline.encode(init_prompt)))
# 调用 save_all_stat 函数保存模型状态和标记列表,键名为 'chat_init',值为 out。
save_all_stat('', 'chat_init', out)
# 执行垃圾回收和清空GPU缓存的操作。
gc.collect()
torch.cuda.empty_cache()
# 创建一个服务器列表 srv_list,其中包含一个名为 'dummy_server' 的服务器。
srv_list = ['dummy_server']
# 遍历服务器列表,对于每个服务器,调用 save_all_stat 函数保存模型状态和token列表,
# 键名包含服务器名和 'chat',值为 out。
for s in srv_list:
save_all_stat(s, 'chat', out)
# 定义一个名为 reply_msg 的函数,该函数接受一个参数 msg,并打印机器人、界面和回复消息。
def reply_msg(msg):
print(f'{bot}{interface} {msg}\n')
# 这段代码定义了一个名为 on_message 的函数,用于处理接收到的消息。
def on_message(message):
# 声明在函数内部使用全局变量 model_tokens、model_state、user、bot、interface 和 init_prompt。
global model_tokens, model_state, user, bot, interface, init_prompt
# 将字符串 'dummy_server' 赋值给变量 srv。
srv = 'dummy_server'
# 将接收到的消息中的转义字符 '\\n' 替换为换行符 '\n',并去除首尾空白字符,将结果赋值给变量 msg。
msg = message.replace('\\n','\n').strip()
x_temp = GEN_TEMP
x_top_p = GEN_TOP_P
# 如果消息中包含 -temp=,执行以下操作:
# a. 从消息中提取 -temp= 后面的值,并将其转换为浮点数类型赋值给 x_temp。
# 从消息中移除 -temp= 部分。
if ("-temp=" in msg):
x_temp = float(msg.split("-temp=")[1].split(" ")[0])
msg = msg.replace("-temp="+f'{x_temp:g}', "")
# print(f"temp: {x_temp}")
if ("-top_p=" in msg):
x_top_p = float(msg.split("-top_p=")[1].split(" ")[0])
msg = msg.replace("-top_p="+f'{x_top_p:g}', "")
# print(f"top_p: {x_top_p}")
# 如果 x_temp 小于等于 0.2,将其设置为 0.2。
if x_temp <= 0.2:
x_temp = 0.2
# 如果 x_temp 大于等于 5,将其设置为 5。
if x_temp >= 5:
x_temp = 5
# 如果 x_top_p 小于等于 0,将其设置为 0。
if x_top_p <= 0:
x_top_p = 0
# 去除消息首尾空白字符。
msg = msg.strip()
# 如果消息等于 '+reset':
if msg == '+reset':
# 加载保存的初始模型状态并将其保存为 out。
out = load_all_stat('', 'chat_init')
# 保存模型状态和token列表。
save_all_stat(srv, 'chat', out)
# 调用 reply_msg 函数打印回复消息 "Chat reset."。
reply_msg("Chat reset.")
return
# use '+prompt {path}' to load a new prompt
# 如果消息以 '+prompt ' 开头
elif msg[:8].lower() == '+prompt ':
# 打印 "Loading prompt..."。
print("Loading prompt...")
try:
# 提取消息中 'prompt ' 后面的内容作为提示文件路径,并将其赋值给变量 PROMPT_FILE。
PROMPT_FILE = msg[8:].strip()
# 加载提示文件,将返回的用户、机器人、界面和初始提示内容分别赋值给变量
# user、bot、interface 和 init_prompt。
user, bot, interface, init_prompt = load_prompt(PROMPT_FILE)
# 对prompt编码和推理
out = run_rnn(fix_tokens(pipeline.encode(init_prompt)))
# 保存模型状态和token列表。
save_all_stat(srv, 'chat', out)
# 打印 "Prompt set up."。
print("Prompt set up.")
gc.collect()
torch.cuda.empty_cache()
except:
# 捕获异常,打印 "Path error."。
print("Path error.")
# 如果消息以 '+gen '、'+i '、'+qa '、'+qq '、'+++' 或 '++' 开头,执行以下操作:
elif msg[:5].lower() == '+gen ' or msg[:3].lower() == '+i ' or msg[:4].lower() == '+qa ' or msg[:4].lower() == '+qq ' or msg.lower() == '+++' or msg.lower() == '++':
if msg[:5].lower() == '+gen ':
# 提取消息中 'gen ' 后面的内容作为新的提示内容,并将其赋值给变量 new。
new = '\n' + msg[5:].strip()
# print(f'### prompt ###\n[{new}]')
# 将模型状态和标记列表重置为空。
model_state = None
model_tokens = []
# 运行RNN模型进行推理,生成回复的输出概率向量,并将其保存为 out。
out = run_rnn(pipeline.encode(new))
# 保存模型状态和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg[:3].lower() == '+i ':
# 提取消息中 'i ' 后面的内容作为新的指令,并将其赋值给变量 msg。
msg = msg[3:].strip().replace('\r\n','\n').replace('\n\n','\n')
# 替换指令中的换行符,将 '\r\n' 替换为 '\n',将连续的两个换行符 '\n\n' 替换为单个换行符 '\n'。
# 构建新的提示内容 new,包括指令和响应模板。
new = f'''
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
{msg}
# Response:
'''
# print(f'### prompt ###\n[{new}]')
# 将模型状态和token列表重置为空。
model_state = None
model_tokens = []
# 运行RNN模型进行推理,生成回复的输出概率向量,并将其保存为 out。
out = run_rnn(pipeline.encode(new))
# 保存模型状态和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg[:4].lower() == '+qq ':
# 提取消息中 'qq ' 后面的内容作为新的问题,构建新的提示内容 new,包括问题和回答模板。
new = '\nQ: ' + msg[4:].strip() + '\nA:'
# print(f'### prompt ###\n[{new}]')
# 将模型状态和token列表重置为空。
model_state = None
model_tokens = []
# 运行RNN模型进行推理,生成回复的输出概率向量,并将其保存为 out。
out = run_rnn(pipeline.encode(new))
# 保存模型状态和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg[:4].lower() == '+qa ':
# 加载保存的初始模型状态并将其保存为 out。
out = load_all_stat('', 'chat_init')
# 提取消息中 'qa ' 后面的内容作为真实消息,并将其赋值给变量 real_msg。
real_msg = msg[4:].strip()
# 构建新的提示内容 new,包括用户、界面、真实消息和机器人。
new = f"{user}{interface} {real_msg}\n\n{bot}{interface}"
# print(f'### qa ###\n[{new}]')
# 运行RNN模型进行推理,生成回复的输出概率向量,并将其保存为 out。
out = run_rnn(pipeline.encode(new))
# 保存模型状态和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg.lower() == '+++':
try:
# 加载保存的模型状态 gen_1 并将其保存为 out。
out = load_all_stat(srv, 'gen_1')
# 保存模型状态和token列表。
save_all_stat(srv, 'gen_0', out)
except:
return
elif msg.lower() == '++':
try:
# 加载保存的模型状态 gen_0 并将其保存为 out。
out = load_all_stat(srv, 'gen_0')
except:
return
# 将变量 begin 设置为 model_tokens 的长度。
begin = len(model_tokens)
# 将变量 out_last 设置为 begin。
out_last = begin
# 创建一个空字典 occurrence。
occurrence = {}
# 循环 FREE_GEN_LEN+100 次,其中 FREE_GEN_LEN 是一个常量,代表自由生成的长度。
for i in range(FREE_GEN_LEN+100):
# 遍历字典 occurrence 中的键。
for n in occurrence:
# 将 out[n] 减去一个计算得到的重复惩罚项。
out[n] -= (GEN_alpha_presence + occurrence[n] * GEN_alpha_frequency)
# 使用 pipeline.sample_logits 函数根据概率向量 out 生成一个标记,并将其赋值给 token。
token = pipeline.sample_logits(
out,
temperature=x_temp,
top_p=x_top_p,
)
# 如果 token 等于 END_OF_TEXT,跳出内层循环。
if token == END_OF_TEXT:
break
# 遍历字典 occurrence 中的键。将 occurrence[xxx] 乘以一个常量 GEN_penalty_decay
for xxx in occurrence:
occurrence[xxx] *= GEN_penalty_decay
# 如果 token 不在 occurrence 中,将 occurrence[token] 设置为 1。
if token not in occurrence:
occurrence[token] = 1
else:
# 否则+1,表示这个token重复次数+1
occurrence[token] += 1
# 如果 msg[:4].lower() == '+qa ',调用 run_rnn 函数,
# 传递 [token] 作为参数,并将返回值赋值给变量 out。
if msg[:4].lower() == '+qa ':# or msg[:4].lower() == '+qq ':
out = run_rnn([token], newline_adj=-2)
else:
# 调用 run_rnn 函数,传递 [token] 作为参数,并将返回值赋值给变量 out。
out = run_rnn([token])
# 使用 pipeline.decode 函数将 model_tokens[out_last:] 解码为字符串,并将结果赋值给 xxx。
xxx = pipeline.decode(model_tokens[out_last:])
# 如果字符串 '\ufffd' 不在 xxx 中
if '\ufffd' not in xxx: # avoid utf-8 display issues
# 打印 xxx,并刷新输出缓冲区。
print(xxx, end='', flush=True)
# 将 out_last 设置为 begin + i + 1。
out_last = begin + i + 1
# 如果 i 大于等于 FREE_GEN_LEN,跳出外层循环。
if i >= FREE_GEN_LEN:
break
print('\n')
# send_msg = pipeline.decode(model_tokens[begin:]).strip()
# print(f'### send ###\n[{send_msg}]')
# reply_msg(send_msg)
# 调用 save_all_stat 函数,将参数 srv、'gen_1' 和 out 传递给它。
save_all_stat(srv, 'gen_1', out)
else:
# 如果 msg.lower() == '+'
if msg.lower() == '+':
try:
# 尝试加载状态信息 load_all_stat(srv, 'chat_pre')。
out = load_all_stat(srv, 'chat_pre')
except:
return
else:
# 加载状态信息 load_all_stat(srv, 'chat'),并将结果赋值给变量 out。
out = load_all_stat(srv, 'chat')
# 对消息 msg 进行处理,去除首尾空格,替换换行符,
msg = msg.strip().replace('\r\n','\n').replace('\n\n','\n')
# 并构造新的消息字符串 new,其中包括用户和机器人的标识符。
new = f"{user}{interface} {msg}\n\n{bot}{interface}"
# print(f'### add ###\n[{new}]')
# 调用 run_rnn 函数,传递 pipeline.encode(new) 作为参数,并将返回值赋值给变量 out。
out = run_rnn(pipeline.encode(new), newline_adj=-999999999)
# 将生成的状态信息 out 保存为 'chat_pre' 的状态信息。
save_all_stat(srv, 'chat_pre', out)
# 这里开始的内容和上一个elif里面的基本一致,就不重复解析了
begin = len(model_tokens)
out_last = begin
print(f'{bot}{interface}', end='', flush=True)
occurrence = {}
for i in range(999):
if i <= 0:
newline_adj = -999999999
elif i <= CHAT_LEN_SHORT:
newline_adj = (i - CHAT_LEN_SHORT) / 10
elif i <= CHAT_LEN_LONG:
newline_adj = 0
else:
newline_adj = min(3, (i - CHAT_LEN_LONG) * 0.25) # MUST END THE GENERATION
for n in occurrence:
out[n] -= (GEN_alpha_presence + occurrence[n] * GEN_alpha_frequency)
token = pipeline.sample_logits(
out,
temperature=x_temp,
top_p=x_top_p,
)
# if token == END_OF_TEXT:
# break
for xxx in occurrence:
occurrence[xxx] *= GEN_penalty_decay
if token not in occurrence:
occurrence[token] = 1
else:
occurrence[token] += 1
out = run_rnn([token], newline_adj=newline_adj)
out[END_OF_TEXT] = -999999999 # disable <|endoftext|>
xxx = pipeline.decode(model_tokens[out_last:])
if '\ufffd' not in xxx: # avoid utf-8 display issues
print(xxx, end='', flush=True)
out_last = begin + i + 1
send_msg = pipeline.decode(model_tokens[begin:])
if '\n\n' in send_msg:
send_msg = send_msg.strip()
break
# send_msg = pipeline.decode(model_tokens[begin:]).strip()
# if send_msg.endswith(f'{user}{interface}'): # warning: needs to fix state too !!!
# send_msg = send_msg[:-len(f'{user}{interface}')].strip()
# break
# if send_msg.endswith(f'{bot}{interface}'):
# send_msg = send_msg[:-len(f'{bot}{interface}')].strip()
# break
# print(f'{model_tokens}')
# print(f'[{pipeline.decode(model_tokens)}]')
# print(f'### send ###\n[{send_msg}]')
# reply_msg(send_msg)
save_all_stat(srv, 'chat', out)
########################################################################################################
总的来看,这段代码是一个循环,用于ChatRWKV系统生成回复消息和更新状态信息。它根据输入消息和模型的状态信息进行一个RNN模式的推理,生成一个回复的token和一个新的状态,然后将生成的回复显示出来,生成的状态则可以在下一次生成中继续使用。代码还包括处理特殊命令以及加载和保存状态信息的逻辑。
0x3. ChatRWKV v2聊天系统指南- 直接说话:聊天,用 + 换个回答
- reset: 通过发送+reset消息,您可以重置聊天。
- 加载新的提示: 使用+prompt {path}可以加载一个新的提示,其中{path}是提示文件的路径。
- 消息类型:
- +gen {text}: 基于{text}生成新的内容。
- +i {instruction}: 根据给定的指令{instruction}产生一个响应。
- +qq {question}: 对于给定的问题{question},生成一个答案。
- +qa {text}: 将{text}作为一个问题,并生成一个答案。
- +++: 继续写下去。
- ++: 换个写法。
除了这些指令之外,还可以调整生成参数:
- -temp=: 调整生成的温度。温度影响生成文本的随机性。较高的温度将导致更多的随机输出,而较低的温度将导致更确定的输出。
- -top_p=: 调整Top-P采样。Top-P采样是选择词汇中概率最高的一部分词进行采样的方法。
这篇文章还有一些ChatRWKV v2系统的模型实现部分,tokenizer部分都没有解析到,但目前篇幅已经比较多了,希望留到下次解析。enjoy ChatRWKV v2!