
深度强化学习为什么在实际当中用的比较少 ?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来自 | 知乎
地址 | https://www.zhihu.com/question/290530992/answer/542682421
作者 | 搬砖的旺财
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
我觉得是这样的,深度强化学习作为一个端到端的结构,出现了问题人们很难去发现到底是哪里出了问题(神经网络是一个黑箱),所以不方便我们去解决问题。不过如果能将DRL做一定程度上的语义理解的话会好一些,例如mobileye团队的自动驾驶方案。当然伯克利大学和OpenAI团队的基于DRL控制的机械臂也算是DRL在实际工程中的一个落地吧。请批评指正~^_^
(PS:昨晚回答这个问题的时候躺在床上,感觉自己没发挥好,昨晚正好看了一篇文章写的挺好的,就把这个问题完善一下。)
DRL堪忧的采样效率
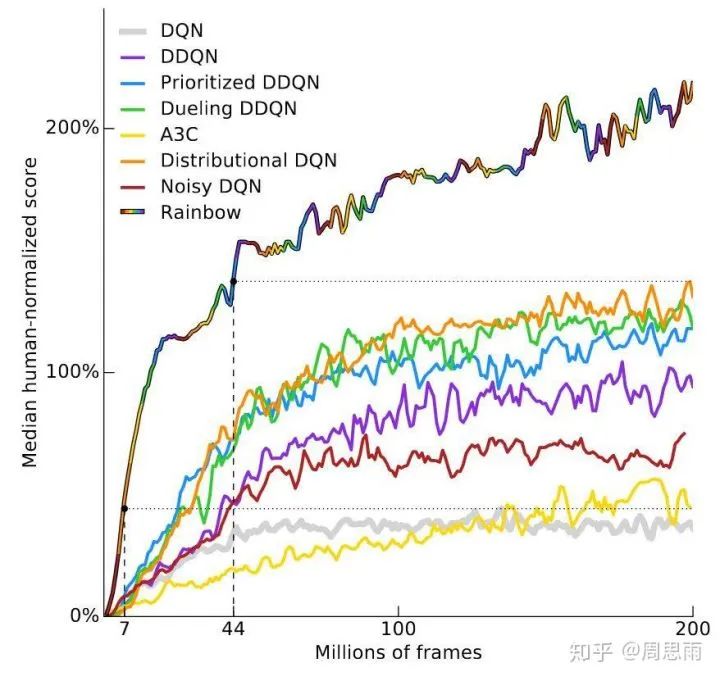
我们可以先看看Deepmind近期的一篇论文:Rainbow: Combining Improvements in Deep Reinforcement Learning。这篇论文对原始DQN框架做了一些渐进式改进,证明他们的RainbowDQN性能更优。在实验中,智能体进行了57场雅达利游戏,并在40场中超越了人类玩家。
上图的y轴是人类玩家表现的中间得分,研究人员观察了DQN在57场比赛的中的表现,计算了智能体得分情况,之后把人类表现作为衡量指标,绘制出智能体性能曲线。
可以看到,RainbowDQN曲线的纵轴在1800万帧时突破100%,也就是超越人类。这相当于83个小时的游戏时间,其中包括训练用时和真实游戏用时,但在大多数时候,人类玩家上手雅达利游戏可能只需要短短几分钟。
需要注意的是,相比较Distributional DQN(橙线)的7000万帧,其实RainbowDQN1800万的成绩称得上是一个不小的突破。要知道就在三年前,Nature刊登了一篇强化学习论文,其中介绍了原始DQN(黄线),而它在实验中的表现是在2亿帧后还无法达到100%。
事实上雅达利游戏并不是唯一的问题。强化学习领域另一个颇受欢迎的基准是MuJoCo基准测试,这是MuJoCo物理模拟器中的一组任务。在这些任务中,系统的输入通常是某个模拟机器人每个关节的位置和速度。但即便是这么简单的任务,系统通常也要经过105—107个步骤才能完成学习,它所需的经验量大得惊人。
如果只关心最终性能,其他方法效果更好
谈及更好的最终效果,DRL的表现有些不尽如人意,因为它实际上是被其他方法吊打的。
关于MuJoCo机器人,通过在线轨迹优化控制,系统可以近乎实时地在线进行计算,而无需离线训练。使用模型预测控制,可以针对地面实况世界模型(物理模拟器)进行规划,而不构建模型的RL系统没有这个规划的过程,因此学习起来更困难。换句话说,如果直接针对某个模型进行规划效果更好,那我们为什么还要花精力去训练RL策略?
同样的,现成的蒙特卡洛树搜索在雅达利游戏中也能轻松超越DQN。2014年,密歇根大学的论文Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning被NIPS收录,它研究的是在实时Atari游戏使用离线蒙特卡洛树搜索的效果。如下图所示,研究人员把DQN的得分和UCT(UCT是如今MCTS的标准版本)智能体的得分相比较,发现后者的性能更加优秀。


RL理论上可以用于任何事情,包括世界模型未知的环境。然而,这种通用性也是有代价的,就是我们很难把它用于任何有助于学习的特定问题上。这迫使我们不得不需要使用大量样本来学习,尽管这些问题可能用简单的编码就能解决。
因此除少数情况外,特定领域的算法会比RL更有效。此外,如果你还对机器人这个问题感到费解,比如DRL训练的机器人和经典机器人技术制作的机器人的差距究竟有多大,你可以看看知名仿生机器人公司的产品——如波士顿动力。

这个双足机器人Atlas没有用到任何RL技术,阅读他们的论文可以发现,它用的还是time-varying LQR、QP solvers和凸优化这些传统手段。所以如果使用正确的话,经典技术在特定问题上的表现会更好。
RL通常需要奖励
RL的一个重要假设就是存在奖励,它能引导智能体向“正确”的方向前进。这个奖励函数可以是研究人员设置的,也可以是离线手动调试的。更重要的是,为了让智能体做正确的事,系统的奖励函数必须准确捕捉研究人员想要的东西。RL有一种恼人的倾向,就是如果设置的奖励过度拟合你的目标,智能体会容易钻空子,产生预期外的结果。
奖励函数设计困难
RL算法关注的是一个连续统一的过程,它假设自己或多或少地了解现在所处的环境。最广泛的无模型强化学习和黑盒优化技术差不多,它只允许假设存在于MDP中,也就是智能体只会被简单告知这样做可以获得奖励+1,至于剩下的,它得自己慢慢摸索。同样的,无模型RL也会面临和黑盒优化技术一样的问题,就是智能体会把所有奖励+1都当做是积极的,尽管这个+1可能是走了邪门歪道。
有的时候研究人员将奖励变得稀疏,当然,有时候这是有效的,因为稀疏的奖励也可以促进学习。但一般情况下,这种做法并不可取,因为积极奖励的缺乏会让学习经验难以稳固,从而训练困难。
另一种解决方法则是更小心地设置奖励,增加新的奖励条件或调整现有的奖励系数,直到机器人不再走任何捷径。但这种做法本质上是人脑和强化学习的博弈,是一场无情的战斗,虽然有时候“打补丁”是必要的,但是我从来没有觉得自己能从中学到什么。
DRL不稳定,结果难以重现
超参数会影响学习系统的行为,它几乎存在于所有机器学习算法中,通常是手动设置或随机搜索调试的。监督学习是稳定的:固定的数据集、实时目标。如果你稍微改变超参数,它不会对整个系统的性能造成太大影响。虽然超参数也有好有坏,但凭借研究人员多年来积累的经验,现在我们可以在训练过程中轻松找到一些反映超参数水平的线索。根据这些线索,我们就能知道自己是不是已经脱离正轨,是该继续训练还是回头重新设计。但是目前DRL还很不稳定,这也成了制约研究的一个瓶颈。
参考文献:
【1】深度强化学习的弱点和局限
请大家批评指正,谢谢 ~
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~