
如何快速挖掘新兴领域需求

挖掘需求的重要性不必多说,有需求才会有市场。
创业者在进入一个新兴领域时会思考这个问题:如何挖掘出用户需求,并做出用户愿意付费的产品。
本文提供一种挖掘新兴领域需求的思路:长尾搜索词。
搜索引擎的搜索框作为用户主动搜索的入口,用户的每个输入都可能是痛点,这些痛点更大概率能转化为需求和产品。
所以我们可以通过收集用户的这些长尾搜索词,并结合一些关键指标,找出需求点。
接下来,我们通过挖掘区块链领域相关需求的例子来讲讲如何操作。
最近比特币等各种虚拟货币大涨,相信大伙或多或少听说过。那么问题来了,区块链经过这些年的发展,作为一个还算新兴的领域,它到底衍生出了哪些产业,创业者进入这个行业能提供哪些服务。
步骤一:确定领域词
首先我们需要确定领域词,领域词的选择至关重要。需要有足够的特征和代表性,不然在后续的扩展挖掘中会越偏越远。
比如区块链行业相关的领域词 「比特币」「Defi」 「以太坊」。
获取行业的领域词,可以有如下办法:
寻找别人整理好的
向相关行业人员请教
自己写程序抓取挖掘
1 和 2 不在本文的讨论中,新兴领域的词层出不穷,整理好的词库有它的滞后性,特别是区块链相关的,项目更新日新月异。还不如自己动手丰衣足食,构建自己的领域词库。
首先找到该领域比较权威的网站或者导航站,比如区块链相关的新闻站有「巴比特」「区块律动」,导航站有 qkl123.com ,我们将导航站收录的项目以及相关的描述都抓取下来。
抓取方式如下
直接用 web scraper 插件(教程可参考我之前写的:如何 5 分钟零代码实现豆瓣小组爬虫 )
用 Python 写个程序。伪代码如下:
URL = https://webapi.8btc.com/qkl/navigation-sites-tag/list?slug=%s&tag_id=&page_size=50&page=%d
循环 slug 和 page:
url = URL + slug + page
返回内容 = 请求数据(url)
抽取返回内容的标题+描述
保存到 txt 文件中最终得到一份 标题+描述 的文本,里面基本能涵盖大部分的领域词,如果觉得这部分不够,可以在其他网站上再采集一些数据。

然后需要从文件中将领域词分离出来,方法就是 分词 + 计算词频 + 抽出 topN 的关键词
我们先尝试使用结巴分词对内容进行分词,一般情况下结巴分词能够比较好的处理中文分词,但是却不适用于我们这种场景。
原因是结巴分词靠的是词典,对于新兴领域词典有滞后性,比如我们测试 区块链是一个伟大的革新,很明显区块链 没有很好的被识别出来。

所以问题变成了如何能够在词库不健全的情况下发现新词(也叫未登录词),解决的方案有很多,下面介绍其中一种算法:左右互信息 + 信息熵。
我们只用通俗的方式去解释原理,具体的公式和代码不涉及。
我们先思考什么样的文本片段能够组成一个词,一般会想到文本片段在语料中出现的次数足够多。
这种方式很容易实现,只要把所有最小单位的片段提取出来,然后计算片段在语料中出现的频数就行。
但光是出现频数高还不够,一个经常出现的文本片段有可能不是一个词,而是多个词构成的词组。比如 赚钱的本质是什么,赚钱 出现的频数高,赚钱的出现的频数也不低,但 赚钱的 并不能成为一个词。
成词标准一:所处语境的丰富程度 - 信息熵
如果一个文本片段在很多的语境中被提到,那么它更有可能成为一个词。
熵就是一个用来衡量这个维度的指标。熵越高就意味着信息含量越大,不确定性越高,越难以预测。
举个例子,被子 是一个词,它可以在各种语境中见到 晒被子 盖被子 被子湿了 但 辈子 只能和 一辈子 半辈子 几个固定搭配,那么 被子 所在语境更加丰富,熵越大,更容易成词。
成词标准二:内部聚合程度 - 互信息
举例说明,我们已经知道 电影是个词,那么 的电影院 拆分两个片段 的电影 电影院,哪个更容易成词呢?
假设在 5000 万字的样本中, 电影 出现了 150 万次, 院 出现了 4 万次。那 电影 出现的概率为 0.03, 院 出现的概率为 0.0008。如果两个片段出现是个独立事件的话,电影、院 一起出现的期望概率是 0.03 * 0.0008 = 2.4e-05。如果 电影院 出现了 3 万次, 电影 院 一起出现的概率是 6e-03, 是期望概率的 250 倍。这通常被成为凝合度,数值越大表示两个片段一起出现的概率越大。而相反 的电影 出现的概率远小于 电影院 ,所以 电影院 更易成词。
综上,想要成为一个词,这两个标准缺一不可。
大概原理讲完了,程序写起来较复杂,我们直接看下运行效果。下图截取部分通过此算法发现的关键词,其中很多是结巴分词没法识别的。看起来效果还不错,基本能涵盖区块链领域的关键词。

步骤二:拓展长尾词
关键词确定后,我们可以围绕关键词扩展出更长尾的词。比如围绕挖矿,可能的需求有 怎么挖矿
挖矿多长时间能回本 挖矿真的能赚钱吗。
那么如何快速拓展出这些长尾词呢,可以思考下,如果我们有类似的问题,会怎么获取信息。
答案是主动搜索 - 问百度,问知乎,问各种搜索引擎。
主动搜索真切的表达了自己当时的需求。
比如我们在百度搜索 挖矿,百度会有一系列的下拉联想词出来,绝大部分是人主动搜索形成的,而这些词背后恰恰体现人们最迫切的需求。
那么接下来问题就简单了,我们只需将步骤一拿到的领域词循环获取下拉词,就能获取到更多的长尾词。获取的方式不赘述,跟上文关键词方式一样,会技术的几行代码就能搞定。
同样我们不用局限于百度,其他的搜索引擎都有类似的功能,另外我们也可以对我们的关键词做下加工,比如加一些情绪词,会有不一样的收获。
步骤三:挖掘长尾词
接下来我们需要寻找出更有价值的长尾词,比如搜索量还行,但竞争不激烈的长尾词。
这个做 seo, sem 的同学都很熟悉,可通过百度关键词规划工具挖掘。
输入相关的关键词,就能看到这个词的月均搜索量,竞争激烈程度。
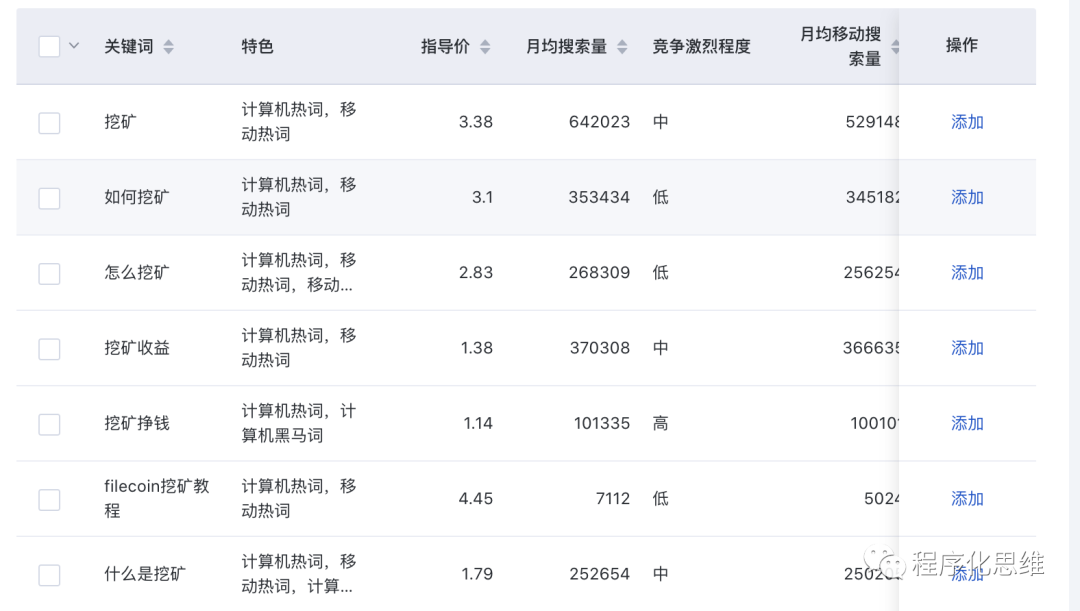
通过上图我们可以看到 挖矿 每个月搜索量很高。说明在区块链领域中 ,挖矿需求真实存在。
很多人可能会执着于挖掘搜索量很高但竞争小的词,会进入一些误区。
不是所有满足条件的关键词就一定能转化成需求,并最终完成变现,它可能是蓝海,也可能不满足需求本身。
反过来,如果你的资源足够,哪怕竞争再激烈,进入一个需求量足够大的市场,也能够分一杯羹。
采用上文同样的方法,我们可循环遍历抓取百度规划师的那部分数据。有一些现成的拓词工具能直接使用,附带搜索量结果。
至此,我们完成了长尾词的挖掘,接下来就是怎么分析这些数据了。
步骤四:聚类长尾词
我们总共跑出了 30w 区块链相关的长尾词,这些词需要做个归类,人工整理耗时耗力,可以写程序帮我们处理大部分工作。
这里介绍一种简单的聚类算法 K-means ,属于无监督算法(Unsupervied learning),即我们手上没有明确的类别,通过算法把相似的东西分到一个组,来寻找其中的规律。
网上有一些很好用的 Python 库,如 scikit-learn 能直接实现 K-means 算法聚类

我们预估分 200个类别,30w 数据 3分钟就能跑完。
效果如下图,我们发现以太币相关的需求已经聚合到同一个文件中
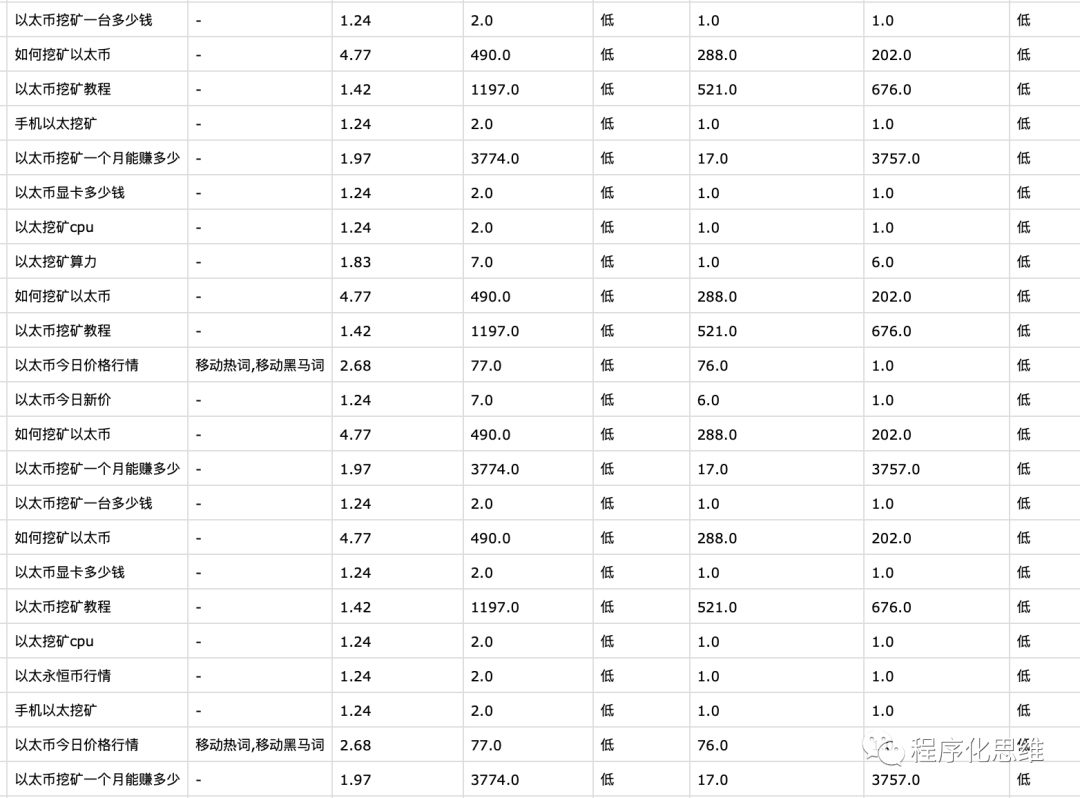
简单分析下数据,区块链行业目前搜索的长尾词用户画像大概分几类 (以下仅供娱乐)
青铜级别 (刚刚知道区块链这个行业,还在将信将疑中)
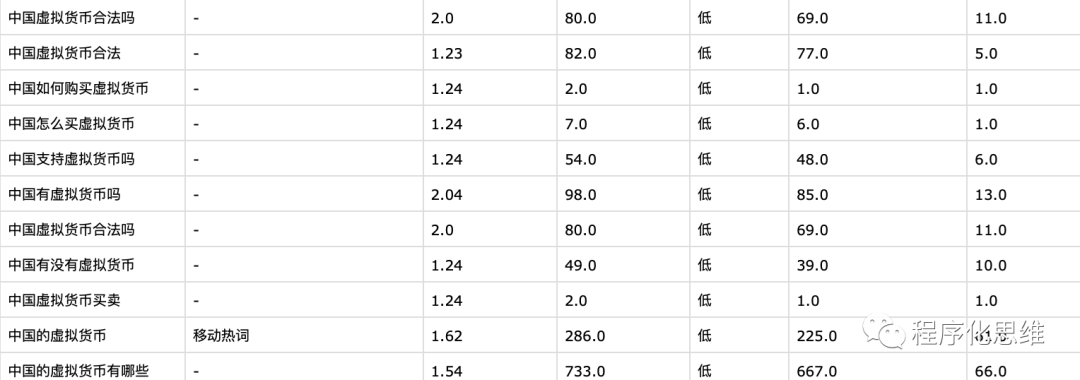
白银级别 (已入场币圈,游走在各种交易所)
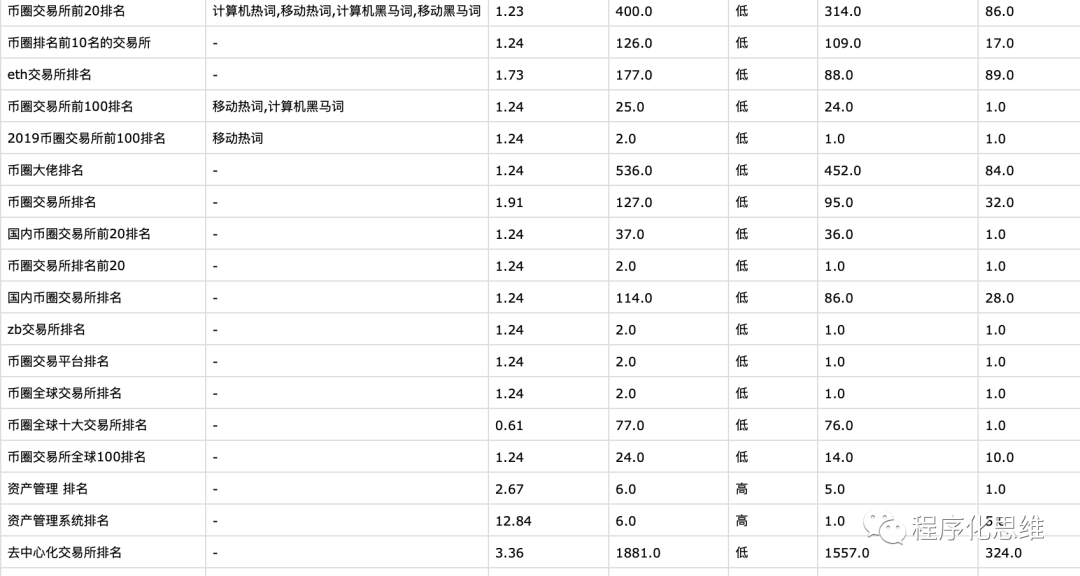
黄金级别 (现货不够刺激,直接上期货)

钻石级别 (不满足交易,开始投资生产力)
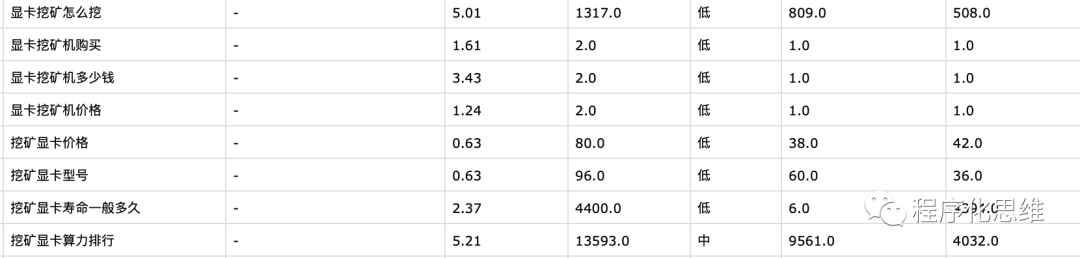
王者级别 (不愿只做韭菜,直接当镰刀)
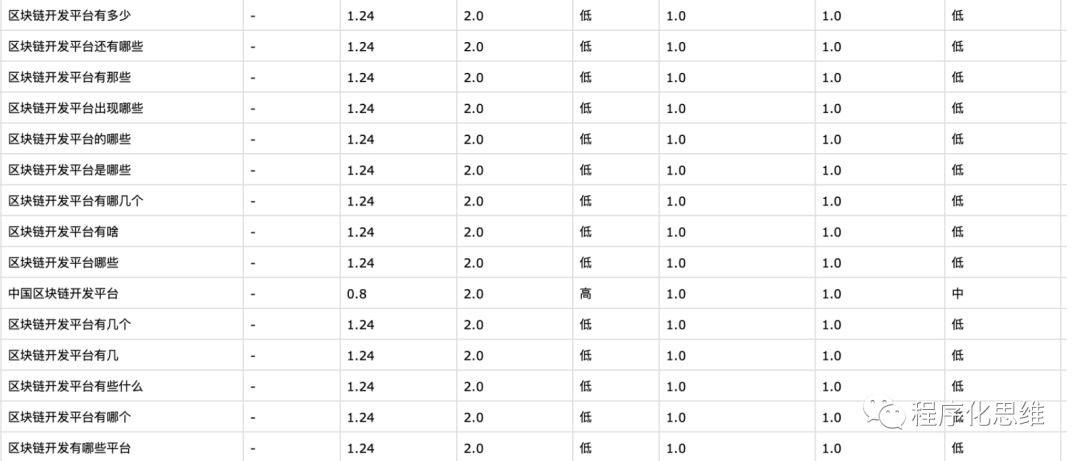
在分析的过程中,我们也发现程序处理流程的几个问题
长尾词覆盖不全
由于区块链行业的特殊,很多关键词没法在规划师中获取到搜索量,故需要另外分析。同时我们确定领域词的时候,可以扩大抓取的数量和范围。
条目跟行业无关
比如 defi 是区块链金融,那么会拓展到金融相关的长尾词,挖矿也会扩展到挖煤矿的长尾词。这个问题可以通过一些思路避免,本文先不赘述,下期再讲。
回顾
有些做技术的同学可能纠结算法的准确率。这里面我的观点是,技术用来给工作提效,但不能纯依赖技术。如果一个算法准确率在 70% 左右,已经能提升一半以上的效率,但再优化这个算法耗费的精力指数级上升,那么可先不优化。
「信息熵+互信息」 算法是我之前的反作弊团队在识别恶意品牌营销上用到的。换个思路,发现它在挖掘需求上面也是把利器。再拓展下,此算法可以挖掘出各行业的品牌词,也能给结巴分词自定义行业词库,细做下去应该也挺有趣。
通过关键词挖掘需求,只是作为一个维度去判断市场,不是万金油。
最后我整理了下此次区块链领域相关的长尾词,如有需要可关注微信公众号「程序化思维」回复区块链获取。
参考链接
如何在百万级的数据里找到别人正在赚钱的项目https://zhuanlan.zhihu.com/p/157846204
反作弊基于左右信息熵和互信息的新词挖掘 https://zhuanlan.zhihu.com/p/25499358
互联网时代的社会语言学:基于SNS的文本数据挖掘 http://www.matrix67.com/blog/archives/5044