
Mybatis查询结果为空时,为什么返回值为NULL或空集合?
共 22131字,需浏览 45分钟
·
2022-07-04 18:40

文章来源:https://c1n.cn/6l7NH
背景
JDBC 中的 ResultSet 简介
简单映射
回归最初的问题:查询结果为空时的返回值
结论
背景
一行数据记录如何映射成一个 Java 对象,这种映射机制是 MyBatis 作为 ORM 框架的核心功能之一,也是我们这篇文章需要学习的内容。
开始前我们先看一个问题:
你是否曾经在学习 Mybatis 的时候跟我有一样的疑问,什么情况下返回 null,什么时候是空集合,为什么会是这种结果?那么你觉得上述这种回答能说服你嘛?
我想应该不能吧,除非亲眼所见,否则真的很难确认别人说的是对还是错(毕竟网上的答案真的千奇百怪,啥都有,已经不是第一次发现一些错误的说法被广泛流传了),那么这篇文章我们就简单的分析一下。
看完这篇你就知道查询结果为空时候为什么集合会是空集合而不是 NULL,而对象为什么会是 NULL 了。
PS:对过程不感兴趣的可以直接跳到最后看结论。
JDBC 中的 ResultSet 简介
你如果有 JDBC 编程经验的话,应该知道在数据库中执行一条 Select 语句通常只能拿到一个 ResultSet,而结果集 ResultSet 是数据中查询结果返回的一种对象,可以说结果集是一个存储查询结果的对象。
while(rs.next()){
// 获取数据
int id = rs.getInt(1);
String name = rs.getString("name");
System.out.println(id + "---" + name);
}
结果集处理入口 ResultSetHandler
当 MyBatis 执行完一条 select 语句,拿到 ResultSet 结果集之后,会将其交给关联的 ResultSetHandler 进行后续的映射处理。
在 MyBatis 中只提供了一个 ResultSetHandler 接口实现,即 DefaultResultSetHandler。
下面我们就以 DefaultResultSetHandler 为中心,介绍 MyBatis 中 ResultSet 映射的核心流程。
public interface ResultSetHandler {
// 将ResultSet映射成Java对象
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
// 将ResultSet映射成游标对象
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
// 处理存储过程的输出参数
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
| handleResultSets
DefaultResultSetHandler 实现的 handleResultSets() 方法就支持多个 ResultSet 的处理,里面所调用的 handleResultSet() 方法就是负责处理单个 ResultSet。
public List<Object> handleResultSets(Statement stmt) throws SQLException {
// 用于记录每个ResultSet映射出来的Java对象
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 从Statement中获取第一个ResultSet,其中对不同的数据库有兼容处理逻辑,
// 这里拿到的ResultSet会被封装成ResultSetWrapper对象返回
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 获取这条SQL语句关联的全部ResultMap规则。如果一条SQL语句能够产生多个ResultSet,
// 那么在编写Mapper.xml映射文件的时候,我们可以在SQL标签的resultMap属性中配置多个
// <resultMap>标签的id,它们之间通过","分隔,实现对多个结果集的映射
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) { // 遍历ResultMap集合
ResultMap resultMap = resultMaps.get(resultSetCount);
// 根据ResultMap中定义的映射规则处理ResultSet,并将映射得到的Java对象添加到
// multipleResults集合中保存
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个ResultSet
rsw = getNextResultSet(stmt);
// 清理nestedResultObjects集合,这个集合是用来存储中间数据的
cleanUpAfterHandlingResultSet();
resultSetCount++; // 递增ResultSet编号
}
// 下面这段逻辑是根据ResultSet的名称处理嵌套映射,你可以暂时不关注这段代码,
// 嵌套映射会在后面详细介绍
...
// 返回全部映射得到的Java对象
return collapseSingleResultList(multipleResults);
}
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) {
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
// 将该ResultSet结果集处理完后的List对象放入multipleResults中,这样就可以支持返回多个结果集了
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}
这里获取到的 ResultSet 对象,会被包装成 ResultSetWrapper 对象,而 ResultSetWrapper 主要用于封装 ResultSet 的一些元数据,其中记录了 ResultSet 中每列的名称、对应的 Java 类型、JdbcType 类型以及每列对应的 TypeHandler。
| DefaultResultHandler 和 DefaultResultContext
在开始详细介绍映射流程中的每一步之前,我们先来看一下贯穿整个映射过程的两个辅助对象 DefaultResultHandler 和 DefaultResultContext。
在 DefaultResultSetHandler 中维护了一个 resultHandler 字段(ResultHandler 接口类型),它默认情况下为空。
比如 DefaultSqlSession#selectList() 中传递的值就是 ResultHandler NO_RESULT_HANDLER = null;
它有两个实现类:
DefaultResultHandler 实现的底层使用 ArrayList<Object> 存储单个结果集映射得到的 Java 对象列表。
DefaultMapResultHandler 实现的底层使用 Map<K, V> 存储映射得到的 Java 对象,其中 Key 是从结果对象中获取的指定属性的值,Value 就是映射得到的 Java 对象。
DefaultResultContext 对象,它的生命周期与一个 ResultSet 相同,每从 ResultSet 映射得到一个 Java 对象都会暂存到 DefaultResultContext 中的 resultObject 字段,等待后续使用。
同时 DefaultResultContext 还可以计算从一个 ResultSet 映射出来的对象个数(依靠 resultCount 字段统计)。
| 多结果集返回
数据库支持同时返回多个 ResultSet 的场景,例如在存储过程中执行多条 Select 语句。
MyBatis 作为一个通用的持久化框架,不仅要支持常用的基础功能,还要对其他使用场景进行全面的支持。
private List<Object> collapseSingleResultList(List<Object> multipleResults) {
// 如果只有一个结果集就返回一个,否则直接通过List列表返回多个结果集
return multipleResults.size() == 1 ? (List<Object>) multipleResults.get(0) : multipleResults;
}
multipleResults 里有多少个 List 列表取决于 handleResultSet() 方法里的 resultHandler == null 的判断。
默认情况下没有设置 resultHandler 的话,那每处理一个 ResultSet 就会添加结果到 multipleResults 中, 此时 multipleResults.size() == 1 必然是不等于 1 的。
注:感兴趣的可以自行查看 resultHandler 什么时候会不为空。
简单映射
DefaultResultSetHandler 是如何处理单个结果集的,这部分逻辑的入口是 handleResultSet() 方法,其中会根据第四个参数,也就是 parentMapping,判断当前要处理的 ResultSet 是嵌套映射,还是外层映射。
无论是处理外层映射还是嵌套映射,都会依赖 handleRowValues() 方法完成结果集的处理。
通过方法名也可以看出,handleRowValues() 方法是处理多行记录的,也就是一个结果集。
handleRowValuesForNestedResultMap() 方法处理包含嵌套映射的 ResultMap,是否为嵌套查询结果集,看 <resultMap> 声明时,是否包含 association、collection、case 关键字。
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) { // 包含嵌套映射的处理流程
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else { // 简单映射的处理
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
// 跳过多余的记录
skipRows(resultSet, rowBounds);
// 检测是否还有需要映射的数据
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
// 处理映射中用到的 Discriminator,决定此次映射实际使用的 ResultMap。
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
该方法的核心步骤可总结为如下:
执行 skipRows() 方法跳过多余的记录,定位到指定的行。
通过 shouldProcessMoreRows() 方法,检测是否还有需要映射的数据记录。
如果存在需要映射的记录,则先通过 resolveDiscriminatedResultMap() 方法处理映射中用到的 Discriminator,决定此次映射实际使用的 ResultMap。
通过 getRowValue() 方法对 ResultSet 中的一行记录进行映射,映射规则使用的就是步骤 3 中确定的 ResultMap。
执行 storeObject() 方法记录步骤 4 中返回的、映射好的 Java 对象。
| ResultSet 的预处理
我们可以通过 RowBounds 指定 offset、limit 参数实现分页的效果。
这里的 skipRows() 方法就会根据 RowBounds 移动 ResultSet 的指针到指定的数据行,这样后续的映射操作就可以从这一行开始。
通过上述分析我们可以看出,通过 RowBounds 实现的分页功能实际上还是会将全部数据加载到 ResultSet 中,而不是只加载指定范围的数据所以我们可以认为 RowBounds 实现的是一种“假分页”。
这种“假分页”在数据量大的时候,性能就会很差,在处理大数据量分页时,建议通过 SQL 语句 where 条件 + limit 的方式实现分页。
| 确定 ResultMap
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix) throws SQLException {
// 用于维护处理过的ResultMap唯一标识
Set<String> pastDiscriminators = new HashSet<>();
// 获取ResultMap中的Discriminator对象,这是通过<resultMap>标签中的<discriminator>标签解析得到的
Discriminator discriminator = resultMap.getDiscriminator();
while (discriminator != null) {
// 获取当前待映射的记录中Discriminator要检测的列的值
final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);
// 根据上述列值确定要使用的ResultMap的唯一标识
final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));
if (configuration.hasResultMap(discriminatedMapId)) {
// 从全局配置对象Configuration中获取ResultMap对象
resultMap = configuration.getResultMap(discriminatedMapId);
// 记录当前Discriminator对象
Discriminator lastDiscriminator = discriminator;
// 获取ResultMap对象中的Discriminator
discriminator = resultMap.getDiscriminator();
// 检测Discriminator是否出现了环形引用
if (discriminator == lastDiscriminator || !pastDiscriminators.add(discriminatedMapId)) {
break;
}
} else {
break;
}
}
// 返回最终要使用的ResultMap
return resultMap;
}
至于 ResultMap 对象是怎么创建的,感兴趣的可以自行从 XMLMapperBuilder#resultMapElements() 方法去了解一下,这里不再赘述。
| 创建映射结果对象
确定了当前记录使用哪个 ResultMap 进行映射之后,要做的就是按照 ResultMap 规则进行各个列的映射,得到最终的 Java 对象,这部分逻辑是在 getRowValue() 方法完成的。
其核心步骤如下:
首先根据 ResultMap 的 type 属性值创建映射的结果对象。
然后根据 ResultMap 的配置以及全局信息,决定是否自动映射 ResultMap 中未明确映射的列。
接着根据 ResultMap 映射规则,将 ResultSet 中的列值与结果对象中的属性值进行映射。
最后返回映射的结果对象,如果没有映射任何属性,则需要根据全局配置决定如何返回这个结果值,这里不同场景和配置,可能返回完整的结果对象、空结果对象或是 null。
这个可以关注 mybatis 配置中的 returnInstanceForEmptyRow 属性,它默认为 false。
当返回行的所有列都是空时,MyBatis 默认返回 null。当开启这个设置时,MyBatis会返回一个空实例。
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 根据ResultMap的type属性值创建映射的结果对象
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
// 根据ResultMap的配置以及全局信息,决定是否自动映射ResultMap中未明确映射的列
if (shouldApplyAutomaticMappings(resultMap, false)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 根据ResultMap映射规则,将ResultSet中的列值与结果对象中的属性值进行映射
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
// 如果没有映射任何属性,需要根据全局配置决定如何返回这个结果值,
// 这里不同场景和配置,可能返回完整的结果对象、空结果对象或是null
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
| 自动映射
创建完结果对象之后,下面就可以开始映射各个字段了。在简单映射流程中,会先通过 shouldApplyAutomaticMappings() 方法检测是否开启了自动映射。
主要检测以下两个地方:
检测当前使用的 ResultMap 是否配置了 autoMapping 属性,如果是,则直接根据该 autoMapping 属性的值决定是否开启自动映射功能。
检测 mybatis-config.xml 的 <settings> 标签中配置的 autoMappingBehavior 值,决定是否开启自动映射功能。NONE 表示关闭自动映射;PARTIAL 只会自动映射没有定义嵌套结果映射的字段;FULL 会自动映射任何复杂的结果集(无论是否嵌套)。
| 正常映射
完成自动映射之后,MyBatis 会执行 applyPropertyMappings() 方法处理 ResultMap 中明确要映射的列。
| 存储对象
通过上述 5 个步骤,我们已经完成简单映射的处理,得到了一个完整的结果对象。
private void storeObject(...) throws SQLException {
if (parentMapping != null) {
// 嵌套查询或嵌套映射的场景,此时需要将结果对象保存到外层对象对应的属性中
linkToParents(rs, parentMapping, rowValue);
} else {
// 普通映射(没有嵌套映射)或是嵌套映射中的外层映射的场景,此时需要将结果对象保存到ResultHandler中
callResultHandler(resultHandler, resultContext, rowValue);
}
}
这里处理的简单映射,如果是一个嵌套映射中的子映射,那么我们就需要将结果对象保存到外层对象的属性中。
如果是一个普通映射或是外层映射的结果对象,那么我们就需要将结果对象保存到 ResultHandler 中。
回归最初的问题:查询结果为空时的返回值
| 返回结果为单行数据
可以从 ResultSetHandler的handleResultSets 方法开始分析。
multipleResults 用于记录每个 ResultSet 映射出来的 Java 对象,注意这里是每个 ResultSet,也就说可以有多个结果集。
我们可以看到 DefaultSqlSession#selectOne() 方法,我们先说结论:因为只有一个 ResultSet 结果集,那么返回值为 null。
步骤如下:
// 检测是否还有需要映射的数据
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next())
public class DefaultResultHandler implements ResultHandler<Object> {
// 默认是空集合
private final List<Object> list;
public DefaultResultHandler() {
list = new ArrayList<>();
}
@SuppressWarnings("unchecked")
public DefaultResultHandler(ObjectFactory objectFactory) {
list = objectFactory.create(List.class);
}
@Override
public void handleResult(ResultContext<? extends Object> context) {
list.add(context.getResultObject());
}
public List<Object> getResultList() {
return list;
}
}
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
| 返回结果为多行数据
那么我们看到 DefaultSqlSession#selectList() 方法,先说结论:返回值为空集合而不是 NULL。
前面都同理,感兴趣的可以自己顺着 executor.query 一路往下看,会发现最后就是调用的 resultSetHandler.handleResultSets() 方法。
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
结论
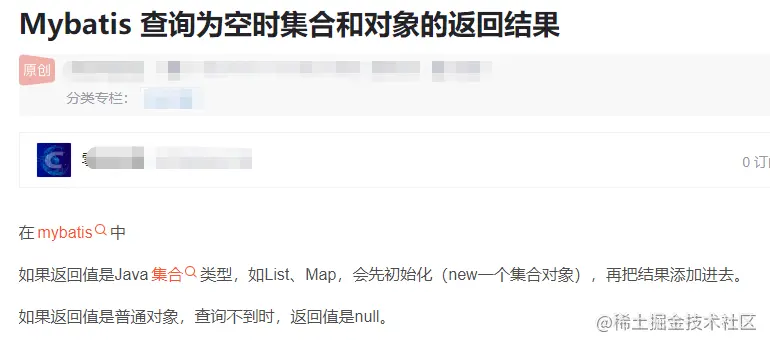
看到这,我们在反过来看上面截图里的答案,什么返回值是 Java 集合会先初始化??而且如果是 Map 作为返回值的话,那直接是返回的 NULL 好吧,简直是错的离谱!
如果返回值是 Java 集合类型,如 List、Map,会先初始化(new 一个集合对象),再把结果添加进去;如果返回值是普通对象,查询不到时,返回值是 null。
其实不管你是查单行记录还是多行记录,对于 Mybatis 来说都会放到 DefaultResultHandler 中去,而 DefaultResultHandler 又是用 List 存储结果。
所以不管是集合类型还是普通对象,Mybatis 都会先初始化一个 List 存储结果,然后返回值为普通对象且查为空的时候,selectOne 会判断然后直接返回 NULL 值。
而返回值为集合对象且查为空时,selectList 会把这个存储结果的 List 对象直接返回,此时这个 List 就是个空集合。