
深度估计相关原理(计算机视觉和深度学习基础)
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
编者荐语
今天来和大家介绍一下深度估计涉及到的理论知识点,包括计算机视觉基础和深度学习基础。
转载自丨3D视觉工坊
一、计算机视觉基础
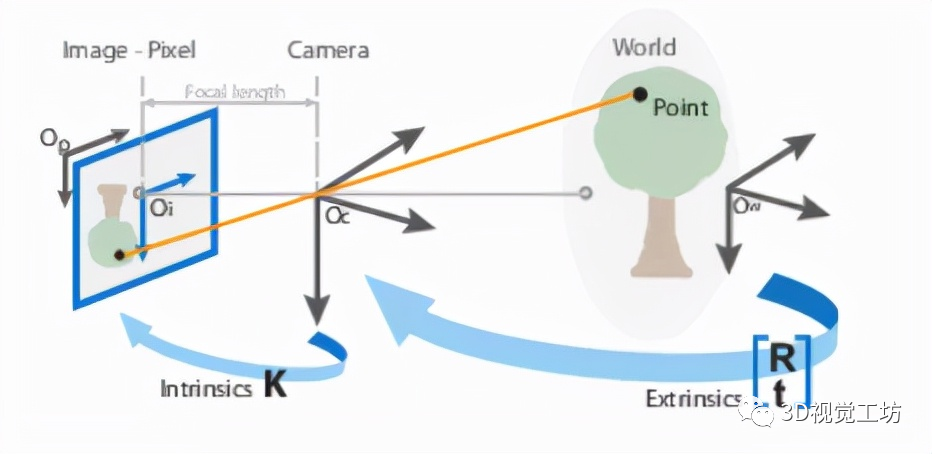
1.1. 针孔相机模型
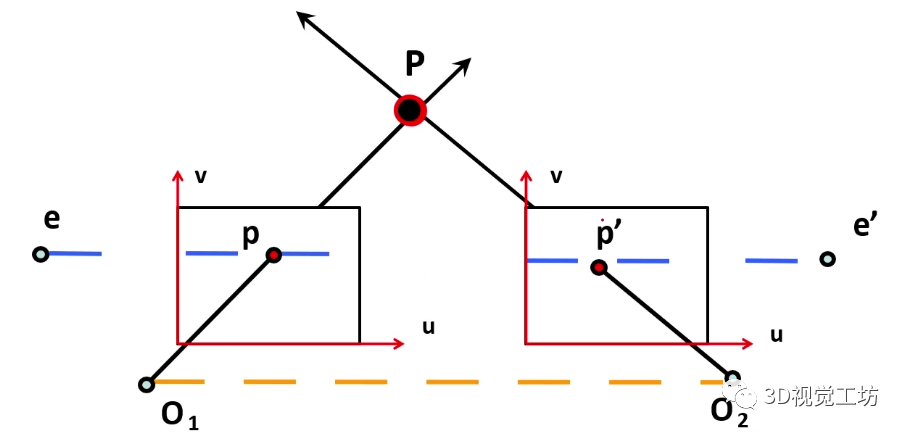
1.2. 对极几何

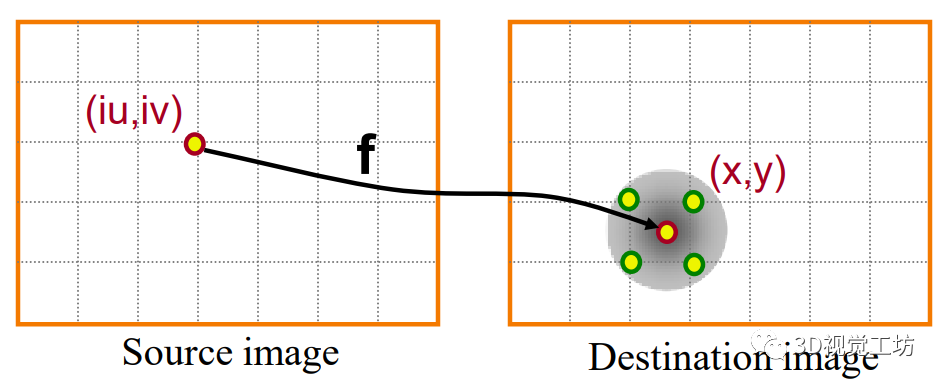
1.3. 图像重构原理

二、深度学习基础
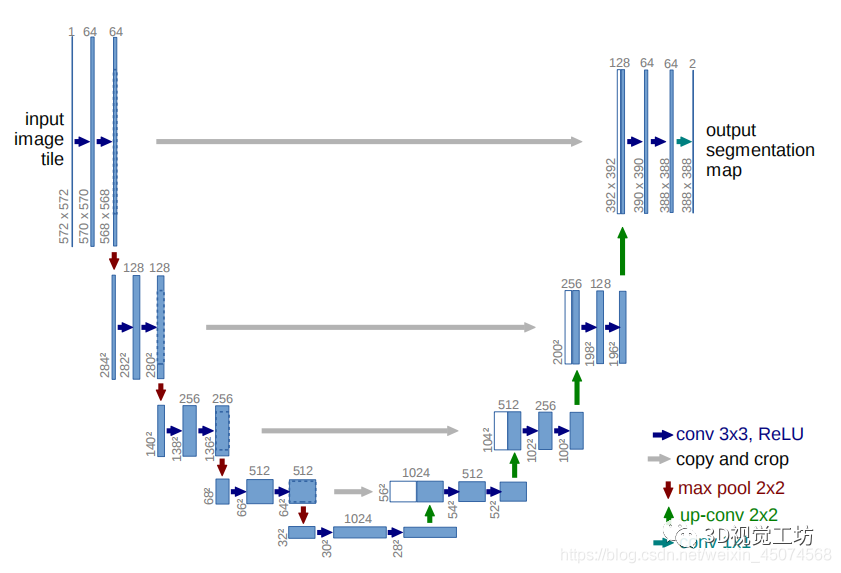
2.1. 相关网络模型

2.2. 深度估计中的损失函数
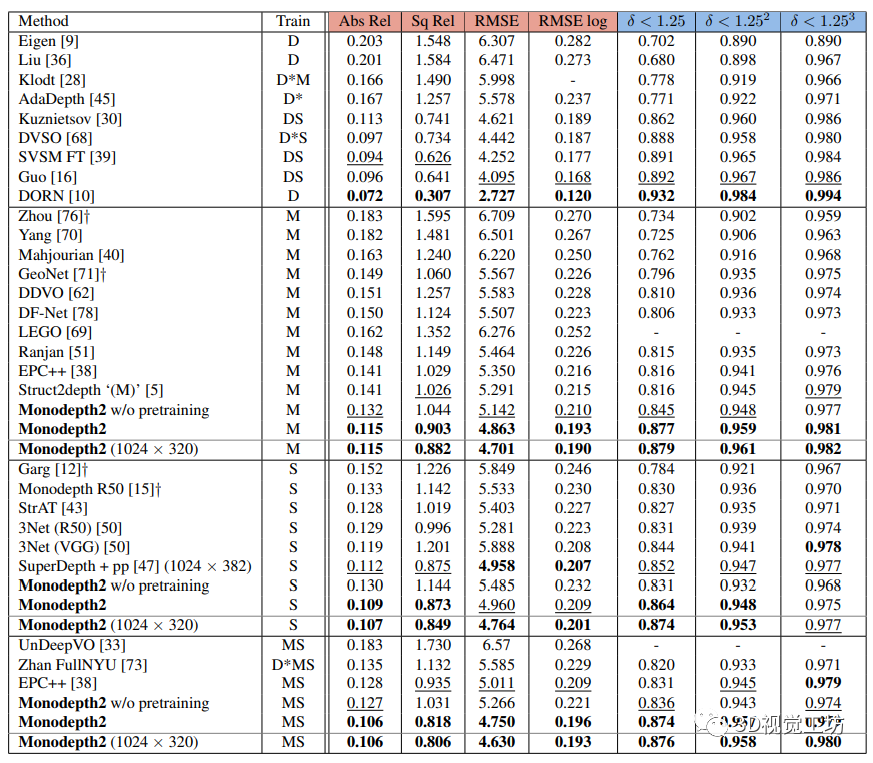
2.3. 深度估计的评价指标
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
评论