
SIGIR2020|图灵奖得主Hinton主题演讲:无监督对比学习将是神经网络的未来

新智元报道
新智元报道
来源:SIGIR
编辑:白峰
【新智元导读】7月27日上午,第43届国际信息检索大会(SIGIR 2020)线上开启,图灵奖得主Geoffrey Hinton作了主题演讲,今天我们就跟随Hinton一起走进「神经网络的新时代」。
人工神经网络一直悬而未决的问题是如何像大脑一样有效地进行无监督学习。
当前有两种主要的无监督学习方法。
第一种方法,以BERT和变分自编码为代表,使用深度神经网络来重建其输入。
第二种方法,是Becker和Hinton在1992年提出的,通过训练一个深层神经网络的两个副本,以相同图像的两种不同剪裁作为输入,产生具有高度互信息的输出向量。设计此方法的目的是使表示形式免受无关细节的束缚。
Becker和Hinton使用的优化互信息的方法也存在缺陷,后面Pacannaro和Hinton虽然用另一个方法替换了它也没能完全解决,但Hinton在本次演讲中提出了一个新的思路。
BERT在语言任务如鱼得水,但在视觉领域行不通
BERT在语言任务如鱼得水,但在视觉领域行不通
本次SIGIR大会上,Hinton首先回顾了自编码器。
自编码器是一种利用反向传播算法使得输出值等于输入值的神经网络,它将原始数据压缩成潜在的空间表征,然后通过这种表征来重构输出。

作为自编码器的典型代表BERT为例,它将句子中的每个词都表示为一种嵌入向量,L+1层通过对比相邻的其他词学到比L层更好的表征,这个更好的表征主要得益于注意力机制。
在到达最后一个激活层softmax之前,词的表征已经非常好了,只需要fine-tune,就能轻松迁移到其他自然语言相关的任务。

「上下文信息是最好的老师」。Hinton举例,「She scromed him with the frying pan」,即使我们没见过「scromed」,通过下文的平底锅,也能大概猜测出「scromed」的意思,拿个平底锅能干啥好事呢?
Hinton认为在视觉领域也是如此,同一批图片的上下文表示,可以提供很强的相关语义信息。
但是BERT这样的编码方式对于图像来说是有问题的,因为网络的最深层需要对图像的精细细节进行编码。

过去20年,为什么有的研究人员认为训练深度自编码器如此困难?Hinton觉得主要有三个原因:
没有采用正确的神经元,修正的线性单元比sigmoid和tanh更合适。
初始化权重做的不好,导致反向传播时的梯度消失或爆炸。
硬件算力不足。

1750亿参数的GPT3,简直了!

无监督对比学习才是神经网络的未来
无监督对比学习才是神经网络的未来
人类大脑有10^14个神经元连接,而人的一生只有10^9秒,因此人类仅靠监督学习是无法完成所有神经元训练的,我们的深度学习模型也是如此,只用监督学习无法取得更新的进展,要将无监督学习融入进来。

当前无监督学习方法过度关注数据的重构损失(Reconstructive Loss),而忽略了数据间关联关系的捕捉。基于此,他提出了下一代神经网络模型的构想,提出利用对比损失函数(Contrastive Loss)建模样本间的局部关系、增强数据间表达的一致性的解决思路。

最后,Hinton展示了自己这一构想的最新实现SimCLR。

SimCLR是一个简单的视觉表示对比学习框架,它不仅比以前的类似工作更出色,而且也更简单。
它首先学习未标记数据集上图像的一般表示,然后可以使用少量标记图像对其进行微调,就能实现特定领域的分类任务。
SimCLR可以通过同时最大化同一图像的不同变换视图之间的一致性以及最小化不同图像的变换视图之间的一致性来学习通用表示。利用这一对比目标更新神经网络的参数,使得相应视图的表示相互「吸引」,而非对应视图的表示相互「排斥」。
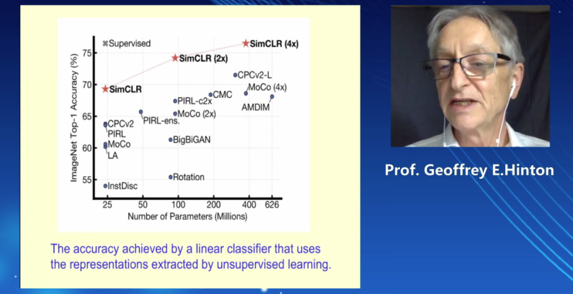
尽管SimCLR 很简单,但是它极大地提高了 ImageNet 上无监督和半监督学习的SOTA效果。基于 SimCLR 训练的线性分类器可以达到76.5% / 93.2%的 top-1 / top-5的准确率,而之前的最好的模型准确率为71.5% / 90.1%。与较小的的监督式学习模型ResNet-50性能相当。
Hinton认为,SimCLR为代表的无监督对比学习将开启神经网络的新时代。