
Hinton团队CV新作:用语言建模做目标检测,性能媲美DETR
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来自|arxiv 编译|机器之心
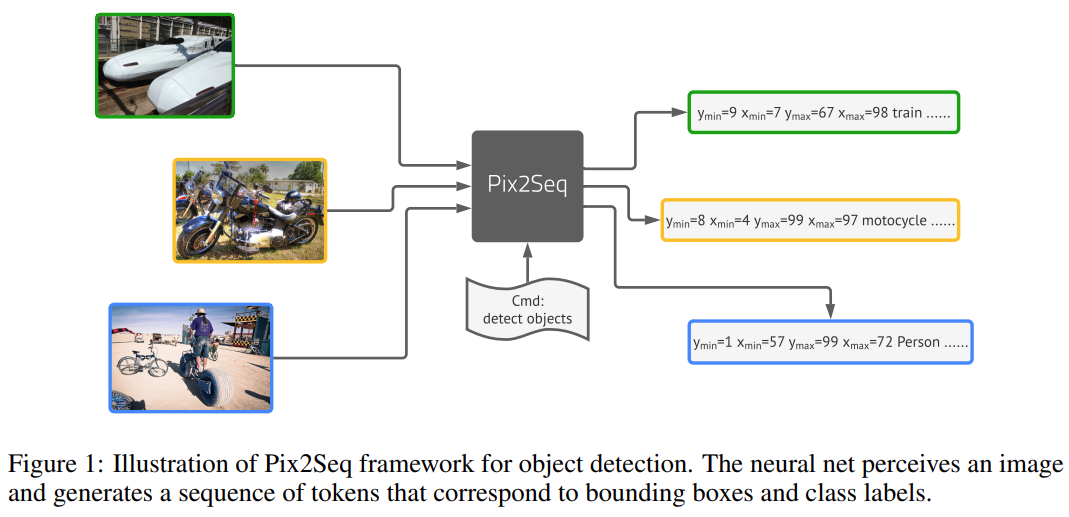
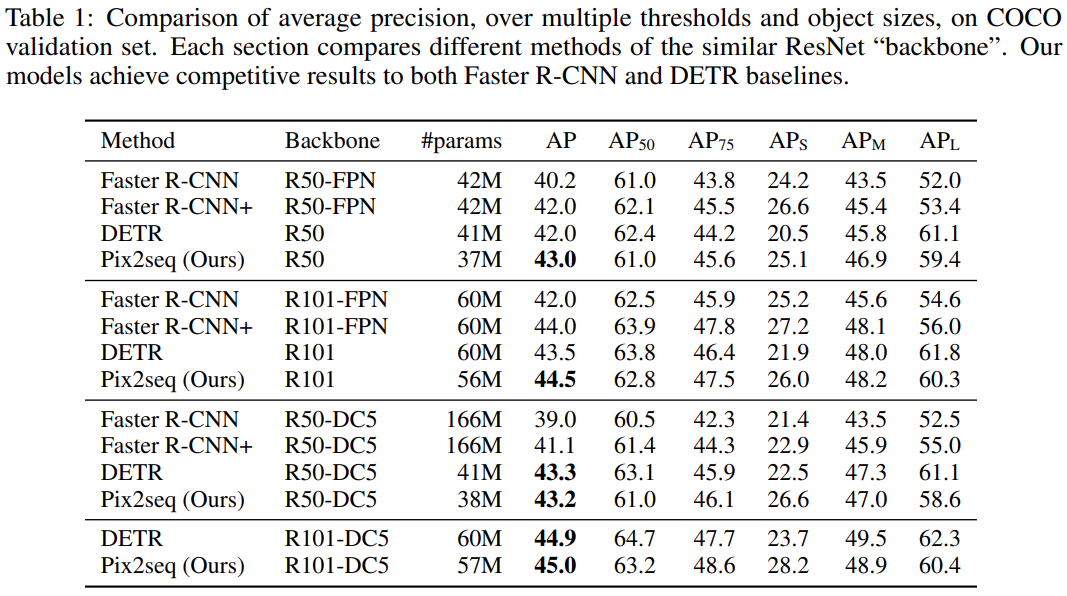
目标检测的「尽头」是语言建模?近日,Hinton 团队提出了全新目标检测通用框架 Pix2Seq,将目标检测视作基于像素的语言建模任务,实现了媲美 Faster R-CNN 和 DETR 的性能表现。

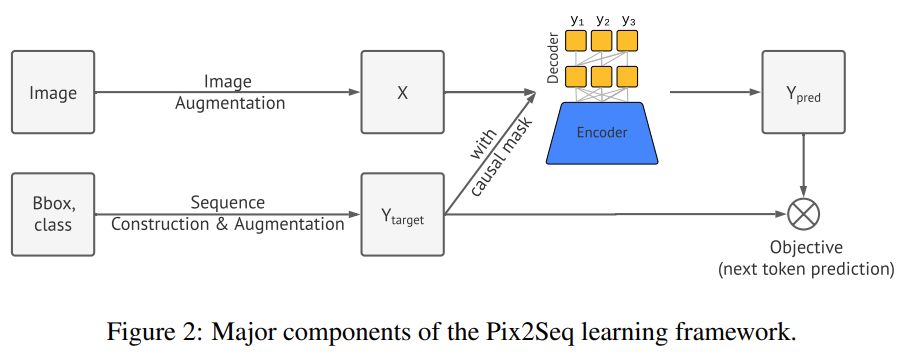
图像增强:在训练计算机视觉模型中很常见,该研究使用图像增强来丰富一组固定的训练样例(例如,随机缩放和剪裁)。
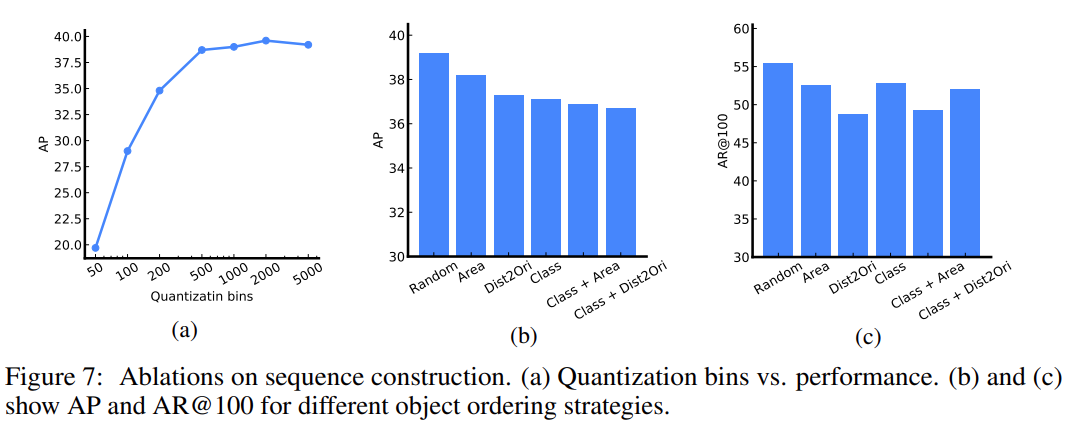
序列构建和增强:由于图像的目标注释通常表征为一组边界框和类标签,该研究将它们转换为离散 token 的序列。
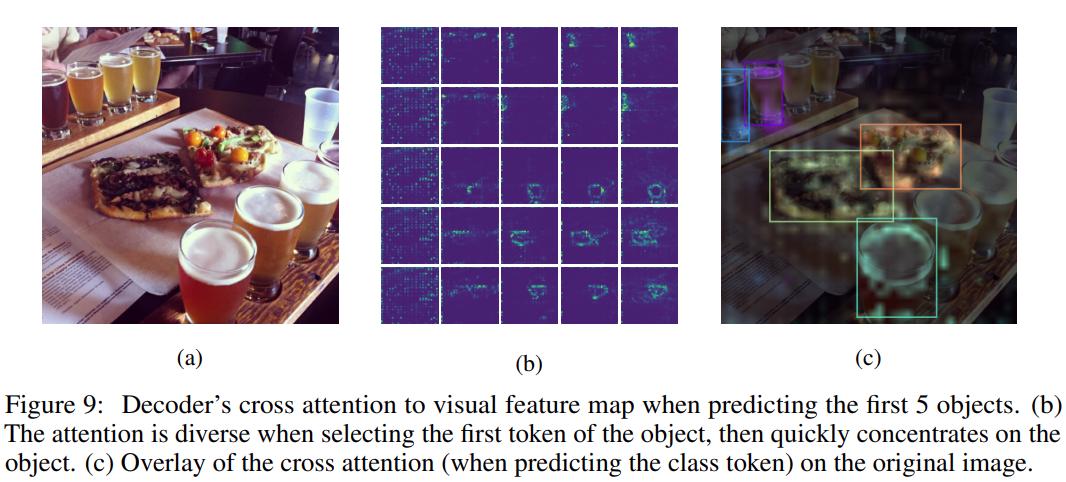
架构:该研究使用编码器 - 解码器的模型架构,其中编码器感知像素输入,解码器生成目标序列(一次一个 token)。
目标 / 损失函数:该模型经过训练以最大化 token 的对数似然。


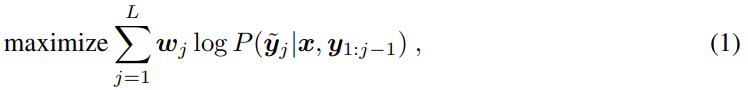
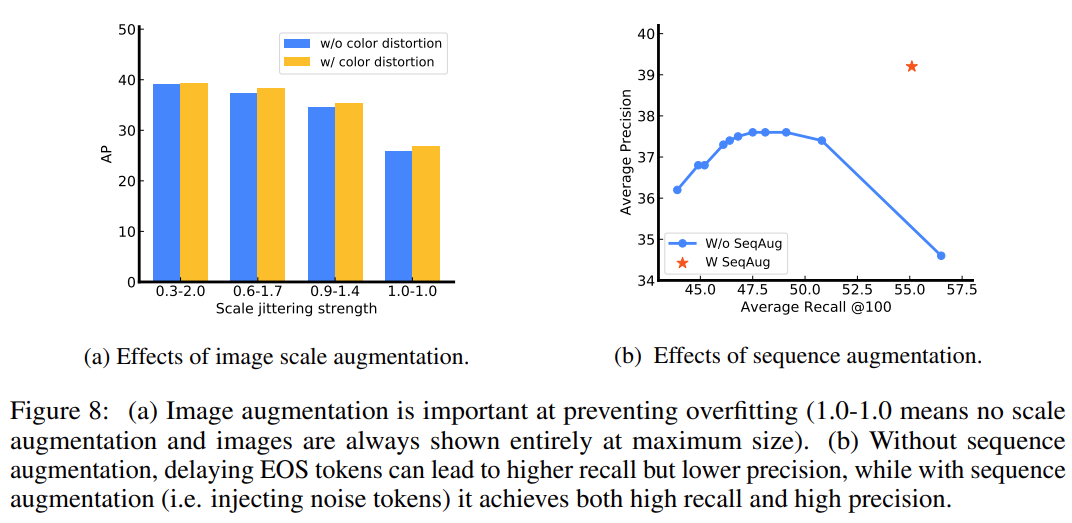
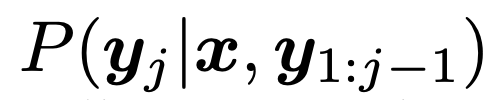 。也可以通过使用最大似然性 (arg max 采样) 的 token,或者使用其他随机采样技术来实现。研究者发现使用核采样 (Holtzman et al., 2019) 比 arg max 采样 (附录 b) 更能提高召回率。在生成 EOS token 时,序列结束。一旦序列生成,它直接提取和反量化了目标描述(即获得预测边界框和类标签)。
。也可以通过使用最大似然性 (arg max 采样) 的 token,或者使用其他随机采样技术来实现。研究者发现使用核采样 (Holtzman et al., 2019) 比 arg max 采样 (附录 b) 更能提高召回率。在生成 EOS token 时,序列结束。一旦序列生成,它直接提取和反量化了目标描述(即获得预测边界框和类标签)。注释噪音(例如,注释者没有标识所有的目标) ;
识别或本地化某些目标时的不确定性。因为召回率和准确率对于目标检测来说都很重要,一个模型如果没有很好的召回率就不可能获得很好的整体性能(例如,平均准确率)。

向现有的地面真值目标添加噪声(例如,随机缩放或移动它们的包围盒) ;
生成完全随机的边框(带有随机相关的类标签)。值得注意的是,其中一些噪声目标可能与一些 ground-truth 目标相同或重叠,模拟噪声和重复预测,如下图 6 所示。


点个在看 paper不断!
评论